自我提问汇总
JDK
HashMap原理?头插法扩容时产生环是什么坑?
https://blog.csdn.net/yang553566463/article/details/108992081
HashMap1.7采用的是头插法,多线程操作时会链表会有环,产生坑,CPU100%。1.8改为了尾插法,并加入了红黑树。不过虽然没有了链表环的等,不过put和get仍然可能冲突,所以时线程不安全的。






Java IO有哪些种类?各自用法?BIO,NIO
Java有哪些基本类型?各自占用长度?
String类实现?String和其他基本类会缓存哪些内容?Intern方法?
字符串常量池,存储在堆。运行时等常量池,存储在元数据区。
StringBuffer和StringBuilder区别?
前者线程安全,后者不安全。直接通过加锁实现。
Java的异常体系图谱?常用异常举例?
错误、运行时异常、受检异常。空指针,数组边界溢出,IO,SQL,找不到类。
常见序列化框架?
Java原生。Json。ProtoBuf。
Java泛型底层原理?
本质是Object,类型信息存在方法的Signiture字段。
Java反射怎么用?原理?
拿到clazz对象。集中方式:object.class,XXClass.class,Class.forname(…)
finally里面的字句一定会被执行吗?
后台线程不会执行。
然后是先return,后finally。
Java动态代理怎么用?底层怎么实现?
关键就是Proxy类和InvocationHandler接口。
Proxy.newProxyInstance(classLoader,targetObj,InvocationHandler)生成动态代理对象。InvocationHandler接口实现invoke(Object proxy, Method method, Object[] args):
Java类初始化执行顺序?
ArrayList?
插入调用了底层,是O(1)
LinkedHashMap?
LRU?
重写removeEldestEntry()即可。默认false。
红黑树?
根节点黑。叶子节点黑(null)。红的儿子全是黑(不允许两个连续红)。每个节点到叶子间的黑节点数量相同。插入的都是红。其实就是2-3-4树的变形,黑节点是真正的节点。https://zhuanlan.zhihu.com/p/139907457 https://zhuanlan.zhihu.com/p/273829162
JDK1.9的模块是什么?用来解决什么问题的?怎么用?(类似maven?)
Java核心类源码:Object,String,HashMap,JUC,Thread?HashMap,IO,还得参照IT技术路再复习下。
JUC/多线程
¥==========AQS原理?
==========线程池原理?实际运用?实现一个简单的线程池?
- 线程名字:便于排查错误。
- 阻塞队列:使用有界队列,避免OOM。
- 线程数量:根据CPU密集或者IO密集,参考使用N+1或2N。
- 执行前后的回调:可以埋点,便于监控线程池执行情况。
- 拒绝策略:一般是让调用的线程自己执行。
原理:while循环,去队列里去callable或runnable来执行。
ThreadPoolExecutor 的执行 execute 的方法分为下面四种情况
- 如果当前运行的工作线程少于 corePoolSize 的话,那么会创建新线程来执行任务 ,这一步需要获取 mainLock
全局锁。 - 如果运行线程不小于 corePoolSize,则将任务加入 BlockingQueue 阻塞队列。
- 如果无法将任务加入 BlockingQueue 中,此时的现象就是队列已满,此时需要创建新的线程来处理任务,这一步同样需要获取 mainLock 全局锁。
- 如果创建新线程会使当前运行的线程超过
maximumPoolSize的话,任务将被拒绝,并且使用RejectedExecutionHandler.rejectEExecution()方法拒绝新的任务。
java线程池的实现原理很简单,说白了就是一个线程集合workerSet和一个阻塞队列workQueue。
¥==========CuncurrentHashMap原理?1.7和1.8区别?
ReentrantLock 与 Sycronized区别?公平锁非公平锁实现?
支持多条件。tryLock 和 wait 支持超时。
非公平锁入队前可以插队。
==========Java线程生命周期?线程状态如何转换?
ThreadLocal原理?
每个线程都有一个threadLocals变量,本质上是一个Map,key是threadLocal的变量名,value是值。不过该map和haspMap底层实现不一样,哈希冲突时用的是线性后查法,而非链表法。
扩展:Go、Java线程模式区别?
一个管程,一个CSP。Java通过共享内存来通信,Go有两种方式,共享内存,或者channel。
死锁原因?如何预防?
- 互斥:无法预防
- 部分占有:一次拿到所有资源。
- 不可抢占:自己拿不到就主动放弃。
- 相互等待:按照顺序,序列化拿锁。
单核机器使用多线程是否有意义?
有意义,例如I/O密集型的情况下。
安全性、活跃性、性能?
原子性、可见性、有序性?
Happen-Before原则?
死锁原因及如何解决?
如何通过日志及工具诊断多线程运行时Bug?
可以通过 jstack 命令或者Java VisualVM这个可视化工具将 JVM 所有的线程栈信息导出来,完整的线程栈信息不仅包括线程的当前状态、调用栈,还包括了锁的信息。多线程程序很难调试,出了 Bug 基本上都是靠日志,靠线程 dump 来跟踪问题,分析线程 dump 的一个基本功就是分析线程状态,大部分的死锁、饥饿、活锁问题都需要跟踪分析线程的状态。
创建多少线程合适?
看CPU还是IO密集型,经验公式是N+1或者2N,具体根据实际CPU时间,以及IO所占比例决定。
读写锁支持升级降级吗?
JVM
new一个对象发生了什么?从加载到初始化完成的整体流程?
- 检查是否有该类,没有就去加载
- 是否初始化
- 分配内存
- 设置对象头信息
- 按构造函数初始化对象
类加载机制?
- 加载:从文件,或是网络等,取决于加载器
- 验证:class格式正确
- 准备:分配内存
- 解析:字面量引用替换为直接引用
- 初始化:初始化
双亲委派?破坏双亲委派?用JDBC、Tomecat举例双亲委派模型?
优先调用父类loadClass()方法:
- Boot:从lib/rt.jar开始
- Ext:从lib/ext/…开始
- System:从CLASSPATH开始
- User:自定义,父类都找不都抛异常后,才调用自己的findClass()来加载类。
破坏双亲委派:
- SPI:JDBC:线程上下文classloader,加载classpath的class。
- 实现方式:重写loadClass()方法即可。
- Tomcat:略。
SPI?
JVM内存模型?哪里会发生OOM?StackOverFlow?如何制造各个位置OOM?栈帧结构?方法区重点描述?直接内存会OOM吗?
- 堆:无限扩充ArrayList,OOM
- 栈:
- 无限申请线程:OOM
- 递归调用方法:stackOverFlow
- 方法区:
- 字符串常量池:String.intern
- 类信息:动态代理创建大量类
- 程序计数器:无
字符串常量池在不同的版本实际上存放的位置也是不同的,在1.6版本时放在方法区,在1.7版本又移到了堆中,而到了1.8版本被移动到元空间。直接内存会OOM:NIO。
如何排查线上OOM故障?CPU占用高如何排查?内存占用高如何排查?
jmap来dump文件
通过内存映像分析工具(如Eclipse MemoryAnalyzer)对Dump出来的堆转储快照进行分析
以下是自己根据理解编的:
===== JAVA OOM 假死问题
现象:K8s里Java程序假死,消息调用没响应
排查:
1.预设参数:打开GC日志、堆快照:
XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<GC-log-file-path>
-XX:+HeapDumpOnOutOfMemoryError(开启堆快照)
-XX:HeapDumpPath=C:/m.hprof(保存文件到哪个目录
2.将GC日志上传至:https://gceasy.io/ ,发现OOM导致重启
3.dump 查看JVM内存分配以及使用情况 定位到pid
jmap -heap pid > /home/test/jmapHeap.txt
通过调用jmap -histo pid 命令查看堆内对象存储情况,发现异常队列
4.dump 查看方法栈信息,定位到具体方法:
jstack -l pid > /home/test/jstack.txt
排查结果:发送消息的准备工作开启了10个线程进行入队操作,消费发送却只开启了1个线程进行出队操作,造成大量消息积压,导致OOM
处理方式:消息发送开启到10个线程
实战:JVM调优?如何监控?要注意哪些参数?
SpringAdmin,Promshus/Grafana,
-Xms(初始堆大小)、-Xmx(最大堆大小)新生代老年代比例,NewRadio:年轻代和年老代将根据默认的比例(1:2)分配堆内存,建议设置为 2 到 4。或年轻代绝对大小,通常会把
-XX:newSize -XX:MaxNewSize设置一样大小。元空间大小:JDK 1.8:
-XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=256m,根据实际情况调整, 可以使用命令jstat -gcutil pid查看当前使用率开启GC 日志
-Xloggc:$CATALINA_BASE/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps记录 GC 日志并不会特别地影响 Java 程序性能,推荐你尽可能记录日志。
设置GC 算法
-XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75GC频次:
jstat -gc 26607 1000 3
定位内存占用:
jmap -histo 18658 | head -n 20
定位CPU占用:
jstack 6937 | grep 645f -A 30
可视化监控:
JVM 监控工具:jvisual: 能做的事情很多,监控内存泄漏、跟踪垃圾回收、执行时内存分析、CPU 线程分析等,而且通过图形化的界面指引就可以完成,接下来我主要讲述 jvisual 如何使用以及如何看内存对象的占用。
Arthas :是阿里提供的一款 Java 开源诊断工具。能够查看应用的线程状态、JVM 信息等;并能够在线对业务问题诊断,比如查看方法调用的出入参、执行过程、抛出的异常、输出方法执行耗时等,大大提升了线上问题的排查效率。
Arthas 提供的程序包是以 jar 的形式给出
java -jar arthas-boot.jar.Arthas 提供了客户端访问程序 Arthas Tunnel Server,这样我们便可以操作 Arthas 了.
解决痛点:
- 偶发问题,很难实时定位。
- 公司规定不能在生产环境操作,很难实时定位。
==========垃圾回收算法?常用垃圾收集器各自实现及特点?G1?三色标记?
Java内存模型?先行发生原则?几个操作?几条规则?
- 顺序性
- 传递性
- volitaile
- sychronize
- 线程start
- 线程join
- 线程中断
- finalized
先行发生原则只是另一种描述而已。
¥==========锁优化有哪些措施?偏向锁、轻量级锁、重量锁原理?
Java 对象是不是都创建在堆上的呢?
逃逸分析可栈上分配,但是Hotspot是分配到堆上。
对象的结构?
对象头,实例数据,对象填充
如何访问定位一个对象?
句柄,直接指针
强引用、软引用、弱引用和虚引用?
- 强引用(Strongly Re-ference):一般的引用。
- 软引用(Soft Reference):活到内存不够。
- 弱引用(Weak Reference):活到下一次GC。
- 虚引用(Phantom Reference):仅仅是一个标记。
JVM状态查看等维护工具命令?
- jps
- jstack:查看或导出 Java 应用程序中线程堆栈信息,有没有死锁等
- jmap:dump 文件,查看堆的情况
- jinfo:参数配置输出
- jstat:jstat -gcutil 2815 1000,堆各区占比情况
- 打开GC日志:对生产性能影响并不大。
此外还有在线调试工具Arthas
重写和重载的区别?
重载是静态分派。重写是动态分派(invokevirtual指令)。Java是静态多分派动态单分派。
Java有哪些编译器?各做什么用?
提前编译器,前端编译器(解语法糖,常量优化,主要是提高编程效率)、即时编译器(性能优化,因为其他语言也跑在上面。客户端C1,方法内联。服务端C2,方法调用/循环调用,逃逸分析(栈上分配,标量替换,同步锁消除)。公共子表达式消除、数据边界检查消除)
volatile的变量什么意思?是线程安全的吗?
保证可见性,禁止指令重排序优化。只保证可见性,不保证原子性。如 volatile a;多个线程同时执行a++。
内核线程、用户线程、混合实现有什么区别?Java采用哪种方式?
MySQL
从高性能、高可用、可扩展几个维度提问:
select语句执行流程?update语句执行流程?整体设计架构?
连接器,缓存,分析、优化、执行。
undolog, redolog_prepare, binlog, redolog_commit。
buffer_pool,change_buffer,orderBy/GroupBy内部临时表…
事务隔离级别?RC、RR?MVCC?脏读、不可重复读、幻读?
幻读:语义问题、数据一致性问题。
关键词:视图:严格递增的事务ID -> 数据版本(事务ID+前一版本引用) -> undo -> 一致性视图 -> 事务ID数组 -> 高低水位。在ID数组内,说明快照时还在活跃,不可读。反之,当时已提交,可读。
为什么mysql选可重复读作为默认的隔离级别?生产用什么隔离级别?可重复读能解决幻读问题吗?
历史原因,binlog日志格式问题,statement格式的日志,会造成主从格式不一致。A先删除,B后插入,B先提交,A后提交。此时数据和binlog语句不一致。如果要用RC,需要使用row格式的日志。
MySQL有哪些锁?
全局锁、表锁、行锁、间隙锁(仅RR隔离级别,(前开后闭])。
==========索引原理?B树和B+树区别?
索引优化思路?最佳实践?Explain各个参数看哪些?
- 普通索引/唯一索引
- 索引覆盖:直接走索引
- 索引下推:提前筛选
- groupBy、orderBy加索引
Explain看type,key,rows,extra
changebuffer和redo log有什么区别?一条语句插入的过程?
前者节省随机读IO,后者节省随机写IO。redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写,数据存到内存并写入日志就算执行成功),而 change buffer 主要节省的则是随机读磁盘的 IO 消耗(多个更新合并后只读少数次磁盘)。change buffer可以看做是redo log的二级承包商?数据页在内存,直接更新内存再写redo log。数据页不在内存,先写到change buffer,change buffer写入redo log,就不用读数据页到内存。
优化器如何选择使用哪个索引?
根据扫描行数(根据统计信息估算来判断索引区分度)、是否使用临时表、是否排序等因素进行综合判断。
查询一条语句,执行得很慢,有可能是哪些原因?怎么操作分析解决?
- 大事务undo回滚大量数据版本。
- 没加索引,索引判断错了。
- 在刷脏页,被锁了。
- 内存不够,如何调参高效利用内存。
- 数据/连接确实多。
线上执行DDL操作?
注意长事务,并注意加上尝试时间。
注意小表热点表问题。
MySQL如何监控各个性能?如何调优?最佳实践?
https://blog.51cto.com/u_15127556/3959710
对于MySQL层面,Buffer pool大小事务写磁盘,binlog落盘的策略,innodb 层的并发读设置 事务隔离级别 默认使用rc 都是会影响到最终的压测写入性能表现。
SSD盘、机械盘。
资源满了怎么办?突然CPU彪升、内存满了、磁盘满了、网络连接数满了、假死、死锁,怎么处理?
1.看慢查询日志:慢查询。计算慢,导致运行时间长。
当然,不想详细的分析 MySQL 指标或者是情况比较紧急的话,可以直接在 slowlog 里面用 rows_sent 和 row_examined 做个简单的除法,比如 row_examined/rows_sent > 1000 的都可以拿出来作为“嫌疑人”处理。这类问题一般在索引方面做好优化就能解决。
2.看processlist:计算量大,导致运行时间长
据量比较大,即使索引没什么问题,执行计划也 OK,也会导致 CPU 100%,而且结合 MySQL one-thread-per-connection 的特性,并不需要太多的并发就能把 CPU 使用率跑满。这一类查询其实是是比较好查的,因为执行时间一般会比较久,在 processlist 里面就会非常显眼
3.看QPS:高 QPS
不论是 row_examined/rows_sent 的比值,还是 SQL 的索引、执行计划,或者是 SQL 的计算量都不会有什么明显问题,只是 QPS 指标会比较高,而且 processlist 里面可能什么内容都看不到,例如:
总结一下
实际上 CPU 100% 的问题其实不仅仅是单纯的 %us,还会有 %io,%sys 等,这些会涉及到 MySQL 与 Linux 相关联的一部分内容,展开来就会比较多了。本文仅从 %us 出发尝试梳理一下排查&定位的思路和方法,在分析 %io,%sys 等方面的问题时,也可以用类似的思路,从这些指标的意义开始,结合 MySQL 的一些特性或者特点,逐步理清楚表象背后的原因。
线上死锁如何排查?如何处理?连接数过高?CPU飙升?磁盘满了?如何处理?
show processlist。Kill。
单机,数据备份怎么做?
参考:
mysqlpump工具,默认导出所有的六类对象:
但mysqlpump导出的备份不是数据一致性快照,因为没有 –lock-all-tables 和 –lock-tables 参数。虽然有 –single-transaction 参数,但默认也off。
如果我们需要使用mysqlpump备份,并且需要数据一致性快照的话,那么我们必须:
- 在pump之前手工使用 FLUSH TABLES WITH READ LOCK 锁住数据库。
- 或者使用–single-transaction 参数,在一个事务中备份。
也可以考虑专门切一个从库出来备份?
恢复操作:
- 更简单一些 直接利用
mysql -uroot -p < 备份的.sql来进行恢复即可:mysqldump -uroot -p123456 --single-transaction -S /tmp/mysql.sock > all_bak.sql
在 MySQL5.7 版本推出了 mysqlpump工具 。 可以理解它是mysqldump的加强版
如何计算MySQL基准性能?
QPS计算:
show global status where Variable_name in('com_select','com_insert','com_delete','com_update');- 等待10秒
show global status where Variable_name in('com_select','com_insert','com_delete','com_update');- 计算差值
TPS计算:
show global status where Variable_name in('com_insert','com_delete','com_update');- 等待10秒
show global status where Variable_name in('com_insert','com_delete','com_update');- 计算差值
IOPS:
- 估算。或者磁盘上有。
机器状态:
- iostat:磁盘、CPU等使用情况。
单机崩溃如何恢复?原理?如何做持久化?binlog、redolog区别联系?两阶段提交?
udolog -> redologPrepare -> binlog -> redologCommit
主从同步如何实现?主从数据一致性问题?如何解决主从数据不一致?半同步?
半同步原理:binlog -> 从relayLog -> ack/commit ->从binlog
https://www.cnblogs.com/jimoer/p/14673646.html
https://juejin.cn/post/6981745007552102407
https://blog.csdn.net/HD243608836/article/details/118221038
MySQL复制类型?
- 异步复制模式:很好理解,很可能丢数据。
- 同步复制模式:所有从ack才commit。
- 半同步复制:有一个从ack就commit。
- 延迟复制:避免逻辑破坏。
- GTID复制(MySQL5.6):从连上主时,把自己已执行的和待执行的(relay_log)GTID发给主即可。
半同步复制:
- master的dump线程不但要发送binlog到从库,还有负责接收slave的ACK
- 当出现异常时,Slave没有ACK事务,那么将自动降级为异步复制,直到异常修复后再自动变为半同步复制。本质上就是主库同步从库,从库响应超时时,主库会自动提交,不再等从库。(
rpl_semi_sync_master_timeout,默认10s,超时降级为异步复制)。当半同步复制发生超时时(由rpl_semi_sync_master_timeout参数控制,单位是毫秒,默认为10000,即10s),会暂时关闭半同步复制,转而使用异步复制。当master dump线程发送完一个事务的所有事件之后,****如果在**rpl_semi_sync_master_timeout内,收到了从库的响应**,则主从又重新恢复为半同步复制。 - 注意使用AFTER_SYNC模式(默认):即5.6版本的新模式,从ack之后才主commit。否则主库宕机时会有重复写两遍事务的问题。
- 5.7新的方式AFTER_SYNC模式也有问题:主库A挂掉时,数据有可能还没写到从库B的relay_log了。所以A重启后变为从库时,redologCommit 会被binlog恢复,此时会多数据。MySQL,在没办法解决分布式数据一致性问题的情况下,它能保证的是不丢数据,多了数据总比丢数据要好。
半同步复制(主先Commit redolog日志,从再同步,从ACK主,主返回客户端成功)的隐患:
事务执行两次:主库提交完后等待从库ACK的过程中,如果Master宕机:
事务还没发送到Slave上:Slave升为主,客户端再次提交,执行成功。之前的Master再次恢复,变为Slave,此时再次执行事务。所以在这个机器上执行了两次事务。
事务还已发送到Slave上:Slave升为主,客户端再次提交,在这台机器上执行了两次事务。
幻读:同一个事务内,主A执行事务commit,从B还未同步。客户端查到主A数据。主A挂掉,B转为主,客户端再查,查不到A。
5.7版本增强半同步(从先同步,主再Commit redolog日志,从ACK主,主返回客户端成功)解决了上述问题,但是引入了新的问题,多数据:
- 多数据:即主虽然没提交,但恢复后为提交状态。主库A挂掉时,数据还未同步到从库B。B切为主。A重启后,虽然A之前的数据虽然还没commit,但是已经写到binlog,此时被自动恢复,之后commit。这部分数据就多出来了。
5.7还优化了线程:
- 5.6版本的半同步复制,dump thread 承担了两份不同且又十分频繁的任务:传送binlog 给slave ,还需要等待slave反馈信息,而且这两个任务是串行的,dump thread 必须等待 slave 返回之后才会传送下一个 events 事务。dump thread 已然成为整个半同步提高性能的瓶颈。在高并发业务场景下,这样的机制会影响数据库整体的TPS
- 独立出一个 ack collector thread ,专门用于接收slave 的反馈信息。这样master 上有两个线程独立工作,可以同时发送binlog 到slave ,和接收slave的反馈。
在传统的复制里面,当发生故障需要主从切换时,服务器需要找到binlog和pos点,然后将其设定为新的主节点开启复制。
GTID复制:
- 数据恢复时会根据GTID自动处理。
- 不支持非事务引擎。
- 集群中所有实例都要支持GTID。
- 只支持GTID,不支持老模式:不像半同步,失败时可以回退为异步。
- GTID是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置;
主从数据不一致?
- 半同步。binlog -> 从relayLog -> ack/commit ->从binlog。
- 强制走主,如果有硬性要求的话。可使用AOP实现,易用。
一主多从,主崩溃了,一个从切为主,其他从怎么跟它同步?
全局事务ID:GTID,快速定位。
主备原理?
mysqldump工具备份
如何备份?
全量备份:使用mysqlpump,备份文件。本质上是insert…select…。是一个SQL文本。注意加 –single-transaction参数。
增量备份:使用mysqlbinlog,备份binlog。本质上是通过 mysqlbinlog 模拟一个 slave 从服务器,然后主服务器不断将二进制日志推送给从服务器。
备份系统还需要一个备份文件的校验功能:备份文件校验的大致逻辑是恢复全部文件,接着通过增量备份进行恢复,然后将恢复的 MySQL实例连上线上的 MySQL 服务器作为从服务器,然后再次进行数据核对。
DB和缓存一致性?
- 更新时,先改DB,再改缓存。
- 改缓存失败时重试,重试失败走MQ队列,直到修改成功。
- 延迟是无法避免的。
主崩溃、从崩溃各有什么影响?主从如何切换?
==========常用高可用集群架构?主从、双主、MMM、MHA、PXC、MGR?
MHA本质上是用来解决一主多从的数据一致性问题的。一主一从的话,直接半同步复制就完了。
MHA底层基于SSH,效率较低,适合20-30台服务器。
大公司要开发自己的套件,以及对于的管理平台。
分库分表?Sharding?Mycat?数据怎么平滑迁移?
前沿数据库技术?分布式数据库?OceanBase?TiDB?
MySQL线上常用参数设置?线上注意什么?见原始文档
- 双1写。即redo log 和 bin log都是每次事务都落盘。
- RR + raw格式的binlog。
- 磁盘IOPS参数:
innodb_io_capacity。 - 打开慢日志记录。
- 配置日志备份:mysqldump工具。
- buffer_pool配大点。
- 连接数配大点。
- 关注脏页IO占比参数,
innodb_max_dirty_pages_pct:刷脏页的IO资源占所有IO资源的百分比。不要超过75%。 - 可考虑重建索引来处理数据空洞问题。
双1写。buffer_pool。打开慢日志记录。
redo log持久化:建议将
innodb_flush_log_at_trx_commit设置成 1 ,表示每次事务的 redo log 都直接持久化到磁盘。这样可以保证 MySQL 异常重启之后数据不丢失。binlog持久化:建议将
sync_binlog设置成 1,表示每次事务的 binlog 都持久化到磁盘。这样可以保证 MySQL 异常重启之后 binlog 不丢失。MySQL隔离级别参数设置:将启动参数
transaction-isolation的值设置成READ-COMMITTED即可。参数查看:可以用
show variables来查看当前的值:show variables like ‘transaction_isolation’建议总是使用
set autocommit=1, 通过显式语句的方式来启动事务。否则长事务会导致大量的回滚日志记录(用于MVCC)。可以配合可以用commit work and chain语法来使用,即提交本次事务并自动开始下一次事务。如何避免无意的长事务:
- 可以在
information_schema库的innodb_trx这个表中查询长事务,如下为查找持续时间超过 60s 的事务:select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60 - 业务连接数据库的时候,根据业务本身的预估,通过
SET MAX_EXECUTION_TIME命令,来控制每个语句执行的最长时间,避免单个语句意外执行太长时间。 - 监控 information_schema.Innodb_trx 表,设置长事务阈值,超过就报警 / 或者 kill;
- 在业务功能测试阶段要求输出所有的 general_log,分析日志行为提前发现问题;
- 如果使用的是 MySQL 5.6 或者更新版本,把 innodb_undo_tablespaces 设置成 2(或更大的值)。如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便。
- 可以在
为什么要重建索引?重建索引,语句怎么写?页分裂等原因,导致数据页有空洞。不论是删除主键还是创建主键,都会将整个表重建,所以不要用drop xx 和 create xx语句重建索引,而且连着执行这两个语句的话,第一个语句就白做了。这两个语句,你可以用这个语句代替 : alter table T engine=InnoDB。
全局锁的命令:
Flush tables with read lock官方自带的逻辑备份工具: mysqldump。当 mysqldump 使用参数
–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图。而由于 MVCC 的支持,这个过程中数据是可以正常更新的。在可重复读隔离级别下开启一个事务,就可以拿到一致性视图了。有些引擎不支持事务,那么只有用全局锁停下来更新。表锁:语法为
lock tables … read/write。与 FTWRL 类似,可以用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放。在还没有出现更细粒度的锁的时候,表锁是最常用的处理并发的方式。例如,在某个线程 A 中执行 lock tables t1 read, t2 write; 此时其他线程不能写t1,不能读写t2。而线程A在unlock tables前,也只能读t1、读写t2,不能访问其他表。元数据锁:无需显式使用,在访问一个表的时候会被自动加上。
- MDL 的作用是锁住表结构,保证读写的正确性。在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
- 修改表结构会进行全数据扫描:修改大表要特别注意。
- 修改表结构会同时申请读写锁:即使修改的是小表,如果该小表访问十分频繁,那么获取锁的过程,以及修改表的操作会阻塞后面所有的读数据操作。此时如果有重试机制,客户端访问超时后如果大量重建session申请,这个库的线程会爆满。
- 如何安全的给热点小表加字段:
- 解决长事务:首先解决长事务,事务不提交,就会一直占着 MDL 锁。在 MySQL 的
information_schema库的innodb_trx表中,查询当前执行中的事务。如果有长事务在执行,考虑先暂停 DDL,或者 kill 掉这个长事务。 - 在 alter table 语句里面设定等待时间:如果在这个指定的等待时间里面能够拿到 MDL 写锁最好,拿不到也不要阻塞后面的业务语句,先放弃,之后再通过重试命令重复这个过程。
- 解决长事务:首先解决长事务,事务不提交,就会一直占着 MDL 锁。在 MySQL 的
两阶段锁协议:在InnoDB事务中,行锁是需要时才会加上,并且要等事务结束才会一起释放。并不是用完就释放。两阶段锁协议对我们的启示是:如果事务中需要锁多个行,那么要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。
解决死锁的两个思路:
- 设置超时时间:死锁时直接进入等待,直到超时。超时时间可通过参数
innodb_lock_wait_timeout来设置,默认50s。 - 开启死锁检测:发现死锁后,主动回滚死锁链条中的某一个事务。将参数
innodb_deadlock_detect设置为 on来开启,默认on。但是它也是有额外负担的,每当一个事务被锁的时候,都要看看它所依赖的线程有没有被别人锁住。
- 设置超时时间:死锁时直接进入等待,直到超时。超时时间可通过参数
buffer pool:数据读入内存是需要占用 buffer pool 的
- 是一块连续的内存,用来存储访问过的数据页面。
- innodb_buffer_pool_size 参数用来定义 innodb 的 buffer pool 的大小
- Innodb 中,数据的访问是按照页/块(默认为16KB)的方式从数据文件中读取到 buffer pool中,然后在内存中用同样大小的内存空间做一个映射
- buffer pool 按照最近最少使用算法(LRU)来管理
- 是 MySQL 中拥有最大的内存的模块
change buffer 用的是 buffer pool 里的内存。change buffer 的大小,可以通过参数
innodb_change_buffer_max_size来动态设置。这个参数设置为 50 的时候,表示 change buffer 的大小最多只能占用 buffer pool 的 50%。MySQL如何开启慢查询日志?
MySQL如何查看执行计划?
可以使用 show index 方法,查看索引的基数:show index from t; 优化器拿到索引基数,就可以根据语句来判断会扫描多少行数。修复索引统计不准确方法:
analyze table t命令重写统计索引信息,即可。如果发现 explain 的结果预估的 rows 值跟实际情况差距比较大,可以采用这个方法来处理。大多数时候MySQL都能正确找到索引。偶尔碰到,原本可以执行很快的语句,就是执行的慢,怎么处理呢?
- 用 force index 强行选择。优点是简单暴力。缺点是1.不优雅灵活。索引名字会改,库也会迁移,可能导致语法不兼容。2.变更不敏捷:一般都是线上发现问题后,才去查看,然后改完还要测试发布。
- 修改SQL语句诱导优化器使用期望的索引:例如把之前的“order by b limit 1” 改成 “order by b,a limit 1”,语义相同。之前之所以不选a而选b,是因为优化器认为b是有序的,可以避免排序。这里我们强制要排序加上a,那么此时两个索引都要排序,所以又通过扫描行数来判断了。
- 直接新建或删除索引来改变优化器行为:某些场景下适用。
总之抓住关键点,优化器会根据扫描行数(可
analyze table保证统计正确)、是否排序(可通过SQL诱导)、是否使用临时表等因素,来综合选择是否走索引,走哪个索引。扫描行数并不是唯一因素。innodb_io_capacity参数代表主机全力刷脏页能多快:InnoDB 需要知道所在主机的 IO 能力,才能知道需要全力刷脏页的时候,可以刷多快。这个值建议你设置成磁盘的 IOPS。磁盘的 IOPS 可以通过 fio 这个工具来测试innodb_max_dirty_pages_pct参数:刷脏页的IO资源占所有IO资源的百分比。尽量避免MySQL抖动的策略是,合理地设置innodb_io_capacity参数的值,并且*平时要多关注脏页比例,不要让它经常接近 75%*。innodb_flush_neighbors参数:“连坐”机制。只在机械硬盘时代有意义,可以减少随机 IO。alter table A engine=InnoDB:使用该命令重建表即可。sort_buffer_size参数:MySQL 为排序开辟的内存(sort_buffer)的大小。tmp_table_size参数:内存临时表大小的参数。默认16M,超过这个大小则转换为磁盘临时表。internal_tmp_disk_storage_engine参数:配置磁盘临时表的引擎,默认 InnoDB。show processlist命令:分析原因,我们一般直接执行show processlist命令,看看当前在执行的语句处于什么状态。怎么查出是谁占着锁呢?MySQL 5.7 版本及以上,可以通过
sys.innodb_lock_waits表查到。max_connections参数:控制一个 MySQL 实例同时存在的连接数的上限,超过这个值,系统就会拒绝接下来的连接请求,并报错提示“Too many connections”。
事务特性?
4个范式?ACID属性?
- 1范式:属性不可再分。
- 2范式:表不可再分。
- 3范式:没有传递依赖。
MySQL常用引擎?
MyISAM, InnoDB, member
什么是覆盖索引?
select * from t where a=1 and b = 2。如果是select a,b,那么更是回表都不需要。
什么是最左前缀原则?
两个索引,最左边的。字符串索引,最左边的部分。
什么是索引下推优化?
select * from t where a=1 and b = 2。如果a和b都有联合索引了,那么会直接在索引处过滤完所有条件,再回表。效率大幅提升。
InnoDB中,行锁什么时候获取到?什么时候释放?两阶段锁协议
update,拿到行锁后,直到事务提交才释放锁。
如何安排正确的事务语句顺序?如果事务中需要锁多行,那么最可能冲突的锁放前面还是后面?为什么?
区分度高的放前面。
举个MySQL死锁的例子?如何解决死锁?
- 设置超时,默认50s。
- 开启死锁检测,死锁自动回滚,默认ON。
如何解决热点数据的死锁检测CPU消耗过高问题?
直接临时关掉死锁检测。或者将一行改为逻辑上的多行。
MVCC如何实现?
快照,事务ID,数据版本,事务可视数组,高低水位。查询时:一致性读。更新时:当前读/阻塞。
更新的时候,更新的是哪个版本的数据?
当前读。看不到也会更新。更新数据都是先读后写的,而这个读,只能读当前的已提交的值,称为“当前读”(current read)。即使不在当前视图里,读的也是最新值。
在 InnoDB 中,每个数据页的大小默认是 16KB。其实可以存近千个key。
用的哪个版本的MySQL?
- MySQL 5.7,(增加了多线程刷delay日志?)增加了mysqlpump备份工具。
MySQL有哪些日志?
https://zhuanlan.zhihu.com/p/516793325
MySQL日志主要分为四类,使用这些日志文件可以查看MySQL内部发生的事情:
- 二进制日志,记录所有更改数据的语句,可以用于主从数据库复制,数据恢复等
- 错误日志,记录MySQL服务的启动、运行或停止MySQL服务出现的问题
- 开启错误日志:在配置文件中添加一行代码:
log_error = /home/lwz/Public/mysql/3306/data/My_Error.log。之后重启服务。 - 查看错误日志:
show variables like "log_error"。一个普通文本文件,可以直接打开。
- 开启错误日志:在配置文件中添加一行代码:
- 通用查询日志,记录建立的客户端连接和执行的语句。默认关闭。通用查询日志记录MySQL的用户的所有SQL操作,是一个普通文本文件。
- 慢查询日志,记录所有执行时间超过long_query_time的所有查询或不使用索引的查询
- 开启慢查询日志:
set @@global.slow_query_log = 1;。默认保存路径,和我们的数据库文件在同一个目录 - 查看慢查询日志:一个普通文本文件,可以直接打开。
- 开启慢查询日志:
默认情况下,所有日志创建于MySQL数据目录中,
Redis
从高性能、高可用、可扩展几个维度提问:
$==========一条set语句执行流程?整体设计架构?何谓单线程?
那张装X的图。
socketService -》IO -》队列-》文件派发器-》连接应答/命令请求/回复
常用数据结构哪些?怎么实现的?如何高效利用?RedisObject等存储结构?
全局哈希表。
数据过期问题?数据淘汰策略?缓存满了怎么办?冷热链?
最新版本的Redis从服务器已经会自己检测过期数据。
设置了超时的数据/不超时的数据,lru, ttl, lfu, random。
脏数据问题?(缓存利用率不高)
缓存击穿、缓存穿透、缓存雪崩?
- 击穿:热点数据不设置超时时间。
- 穿透:布隆过滤器。缓存空对象。
- 雪崩:超时时间一定范围内随机。
缓存抖动?一般是由于缓存节点故障导致。业内推荐的做法是通过一致性Hash算法来解决。
缓存预热?
Redis线上主要用在哪些地方?
登录。元数据。分布式锁。
Redis具备事务特性吗?
- 不支持回滚。
原子性执行到了一半挂了就不支持。持久性也不支持。
单机挂掉怎么恢复?如何持久化?RDB与AOF日志区别?是怎么记载的?
- RDB快照。需要bgsave + copy on write写时复制。
- AOF追加。
- 需要重写,fork出后台的bgrewriteaof子进程,默认64M时重写,可配置。
- 同步写回(几乎不丢,因为不像MySQL是两阶段提交?)、每秒写回、只是写到filesync,由OS决定何时写回。
- 有新数据写入:主线程就会将命令记录到两个aof日志内存缓冲区中。
- AOF重写日志期间发生宕机的话,因为日志文件还没切换,所以恢复数据时,用的还是旧的日志文件。
主从同步原理?如何解决主从数据不一致?崩溃后怎么恢复?主从切换过程?
Redis 可以使用主从同步、从从同步。第一次同步时,主节点做一次 bgsave,并同时将后续修改操作记录到内存 buffer,待完成后将 RDB 文件全量同步到复制节点,复制节点接受完成后将 RDB 镜像加载到内存。
加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。
Redis 集群支持的主从复制,数据同步主要有两种方法:一种是全量同步,一种是增量同步。
1. 全量同步
刚开始搭建主从模式时,从机需要从主机上获取所有数据,这时就需要 Slave 将 Master 上所有的数据进行同步复制。复制的步骤为:
- 从服务器发送 SYNC 命令,链接主服务器;
- 主服务器收到 SYNC 命令后,进行存盘的操作,并继续收集后续的写命令,存储缓冲区;
- 存盘结束后,将对应的数据文件发送到 Slave 中,完成一次全量同步;
- 主服务数据发送完毕后,将进行增量的缓冲区数据同步;
- Slave 加载数据文件和缓冲区数据,开始接受命令请求,提供操作。
2. 增量同步
从节点完成了全量同步后,就可以正式的开启增量备份。当 Master 节点有写操作时,都会自动同步到 Slave 节点上。Master 节点每执行一个命令,都会同步向 Slave 服务器发送相同的写命令,当从服务器接收到命令,会同步执行。如果从挂了,回暂时缓存在环形区。
主从切换:哨兵投票主客观下线,哨兵选leader决定由谁切换,选主打分(延迟、进度等),切换。哨兵之间通过订阅频道通信。
主从切换导致数据丢失如何处理?
DB与Redis数据一致性如何处理?
- 先删除DB,再写Redis
- 要求强一致,那就加锁呗?
==========哨兵模式原理?崩溃后怎么恢复?
主客观下线 -》投票哪个哨兵执行-》选择(响应时间等)-》切换
- 集群监控:对 Redis 集群的主从进程进行监控,判断是否正常工作。
- 消息通知:如果存在 Redis 实例有故障,那么哨兵可以发送报警消息通知管理员。
- 故障转移:如果主机(master)节点挂了,那么可以自动转移到从(slave)节点上。
- 配置中心:当存在故障时,对故障进行转移后,配置中心会通知客户端新的主机(master)地址。
哨兵本身挂掉怎么办?
==========RedisCluster原理?一致性Hash设计原理?如何平滑扩充?崩溃后怎么恢复?
$==========分布式锁如何使用?SetNx?RedLock?和ZK区别?
见后文分布式部分。
https://blog.csdn.net/hh1sdfsf56456/article/details/79474434
单机SetNx:会有两个问题:
- 主挂了:客户端1从主拿到了锁,数据还没同步到从,主挂了,从起来。客户端2在从上获得了锁。
- 超时:客户端1拿到锁,客户端自己阻塞,或访问锁资源超时,锁被释放。但是此时客户端1有可能还在操作锁资源。
RedLock:能解决上述的问题1,但不能解决问题2。
- 逻辑:
- 按照时间顺序,依次请求每个节点获取锁。
- 每个请求都有超时时间,超时则立即请求下一个。
- 当获取到支持的节点数大于1/2,且锁的(实际有效时间 = 锁有效时间 - 总的获取锁的时间)>0,锁有效。
- 细节:
- 依赖持久化,某一个节点挂了需要延迟重启:假设ABCDE节点,客户端1获得了ABC节点,获取锁成功。此时C挂掉,由于锁信息没有持久化,C再起来。客户端2获得CDE节点,同样获得了锁。上述情况,需要C挂掉,然后超过锁有效时间后,再重启。
- 释放锁时候需要对所有节点释放:例如,客户端成功获取ABD节点,获取锁成功。它获取C时,其实可能是已经获取锁成功,但是C返回它结果的时候,阻塞超时了,此时客户端以为没获得C,其实是获得了。
- 问题:s
- 解决了上述,主挂了的问题。
- 仍然没解决客户端超时问题。
- 依赖时序。如果集群某个节点发生大的时间跳跃,可能会产生问题。
缓存命中率低怎么解决?
改用LFU策略。
线上执行很慢,什么原因?
- 本身数据就大。
- 数据结构问题。
- 重写AOF
- 操作集合时,使用SCAN,避免使用Keys。
- 日志、磁盘、内存不足?持久化?。。。
实战:如何调优?有哪些参数要注意?
数据结构。
内存碎片?
用的哪个版本?
redis 5。6支持多路复用。
如何处理 Redis 集群中 big key 和 hot key?
对于 big key 先分析业务存在大键值是否合理,如果不合理我们可以把它们拆分为多个小的存储。或者看是否可以使用别的存储介质存储这种 big key 解决占用内存空间大的问题。
对于 hot key 我们可以在其他机器上复制这个 key 的备份,让请求进来的时候,去随机的到各台机器上访问缓存。所以剩下的问题就是如何做到让请求平均的分布到各台机器上。
是
RabbitMQ
从高性能、高可用、可扩展几个维度提问:
MQ业务上用来做什么?
RabbitMQ如何初始化?
如何避免消息堆积?
- 动态扩容消费者。
- 或者手动创建n个新队列,把积压的消息导过来,再分发出去消费。
如何确保消息送达?丢消息怎么办?死信队列?
confirm 机制
- 在生产者那里设置开启 confirm 模式后,你每次写的消息都会分配一个唯一的 ID。如果写入 RabbitMQ 成功后会回传一个 ack 消息,告诉你这个消息已经到达 RabbitMQ 了;如果没收到你的消息或者失败了,则会回调你的一个 nack,告诉你这个消息 RabbitMQ 接受失败,然后你就可以继续重试发送,而且你可以结合这个机制在内存里维护一个 ID 的状态。如果超过一定时间没收到回调,那么就可以再次发送消息。所以一般在生产者这方避免数据丢失,都是使用 confirm 机制。
RabbitMQ 搞丢数据
RabbitMQ 接收到消息,默认是放在内存里,如果系统挂了或者重启,那对应的消息就会丢失。所以选择开启持久化,把消息写入磁盘中,这样就算系统挂了或者重启都不会丢失消息。
持久化的两个步骤:
- 创建 queue 的时候将其设置为持久化,这样就可以保证 RabbitMQ 持久化 queue 的元数据,但是它不会持久化 queue 里的数据。
- 将消息 deliveryMode=2,即将消息设置为持久化,此时 RabbitMQ 会将消息持久化到磁盘中去。
上面两个持久化必须同时设置才行。这个 RabbitMQ 就算挂了,再次重启的时候也会从磁盘上重启恢复 queue 和 queue 里的数据。
消费端搞丢消息数据:消费端手动ack
如何处理重复消息?
幂等性。
如何确保消息有序?一个Queue,N个consumer的情况?
一个Queue,只能1个consumer。要么拆成很多队列,要么一起接到应用内,再拆。
服务器挂了怎么办?如何持久化?如何恢复?
镜像模式。
集群如何搭建?主从如何同步?挂了一个怎么办?
如何选型?线上指标监控?线上问题排查?核心参数配置?其他最佳实践?
用的哪个版本?3.7
SpringIOC
IOC解决什么问题?哪些注入方式?
封装复杂依赖、多态便于实现类扩展、避免了对象重复创建、便于单元测试。
构造方法注入。Setter注入。接口注入(个人理解这个相当于是吧Setter()方法抽出来作为一个接口而已)。
Spring的文档上说:
DI exists in two major variants, Constructor-based dependency
injection and Setter-based dependency injection.
我的理解是,接口注入其实也是通过setter注入来实现的:
interface InjectPerson {
public void injectHere(Person p);
}
class Company implements InjectPerson {
Person injectedPerson;
public void injectHere(Person p) {
this.injectedPerson = p;
}
}
$==========IOC原理、框架、源码:让你来实现一个IOC容器?怎么实现?有哪些思路?
IOC就是一个大工厂。标记依赖(代码/XML/注解)、创建对象,管理依赖……
$==========IOC流程:初始化流程?有哪些扩展点?
ApplicationContext context = new ClassPathXmlApplicationContext("aspects.xml", "daos.xml", "services.xml");- 配置元数据 –>
BeanDefinitionReader–>BeanDefinition–>BeanDefinitionRegistry–>BeanFactoryPostProcessor - BeanFactoryPostProcessor扩展点:更改信息,如注入特定的休息日,转换YYYYMMDD格式等。
$==========Bean生命周期?三级缓存?循环依赖?构造方法注入或多例能解决吗?
生命周期:
- BeanFacotryPostProcessor
- InstantiationAwreBeanPostProcessor(postProcessorBeforeInstantiation读取Advisor信息,bean实例化,bean依赖注入,postProcessorAfterInstantiationaware组件注入)
- BeanPostProcessor(postProcessorBeforeInitialization,自定义init方法,postProcessorAfterInitialization动态代理实现)
三级缓存:
- 第一层缓存(singletonObjects):单例对象缓存池,已经实例化并且属性赋值,这里的对象是成熟对象;
- 第二层缓存(earlySingletonObjects):单例对象缓存池,已经实例化但尚未属性赋值,这里的对象是半成品对象;
- 第三层缓存(singletonFactories): 单例工厂的缓存
@Autowired是Spring的注解ByType,@Resource是JavaEE标准注解ByName。
Spring推荐使用构造方法注解。但是循环依赖问题,构造方法注入,或者多例的情况,是没办法解决的。Spring认为有循环依赖大概率是程序设计不合理,所以没解决构造方法的问题。
scope属性:对象的作用域,或生命周期。即对象所处的限定场景或存活时间。容器在对象进入其相应的scope之前,会生成并装配这些对象,在该对象不再处于这些scope的限定之后,通常会销毁这些对象。Spring的scope类型有:singleton和prototype。2.0后引入了只用于Web应用的另外三种:request、session和global session类型。bean相当于是构建对象的模板,而scope则指明需要根据这个模板构造多少对象实例,又该让这些构造完的对象实例存活多久。
- singleton:单例。第一次访问生成,存放于容器,存放IOC容器注销。
- *prototype:每次请求一个,交给请求方,不放在容器。
- request:每个HTTP请求创建一个,类似prototype。
- session:每个session创建一个。
- global session:基于
portletMVC ,是Spring提供的另外一套组件。用在普通的基于servlet的Web应用中时,容器会把它看作是普通的session。在传统Servlet/JSP应用中,请求和展示总是一起被执行的。在Portlet应用中,情况发生了改变:当doView或doEdit被调用的时候,仅展示部分被调用。这造成了在Portlet应用中处理与展示两个部分的执行频率并不相同,也就造成了Portlet应用的两阶段处理模式。 - 自定义scope:request、session和global session都实现了
org.springframework.beans.factory.config.Scope接口。
Bean Factory 和 ApplicationContext 有啥区别?
- BeanFactory:提供基础的IoC容器服务。默认采用lazy-load,启动快。对象用到的时候才会生成及绑定。
- ApplicationContext。间接继承自BeanFactory,并扩展了其它功能接口。提供了事件发布等高级特性。对象在容器启动后就已全部加载完成。
- 自动加载所有bean。
- 国际化。
- 资源加载。
- 事件机制。
FactoryBean用来做什么?
解决注入问题。如果属性字段声明的是一个接口,那么具体的对象创建逻辑则由FactoryBean来提供。在xml声明为FactoryBean,返回的则是具体的Bean,而不是factoryBean。
@Resource和@Autowired区别
前者为JSR的标准,后者为Spring特有。前者默认byName查找,找不到时回退为byType。后者默认byType,找不到时报错,找到多个时需要用@Qualifier注明,否则报错。
(1)处理这2个注解的BeanPostProcessor不一样
CommonAnnotationBeanPostProcessor是处理@ReSource注解的
AutoWiredAnnotationBeanPostProcessor是处理@AutoWired注解的
(2)@Autowired只按照byType 注入;@Resource默认按byName自动注入,也提供按照byType 注入;
(3)属性:@Autowired按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。@Resource有两个中重要的属性:name和type。name属性指定byName,如果没有指定name属性,当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。需要注意的是,@Resource如果没有指定name属性,并且按照默认的名称仍然找不到依赖对象时, @Resource注解会回退到按类型装配。但一旦指定了name属性,就只能按名称装配了。
@Resource装配顺序
1. 如果同时指定了name和type,则从Spring上下文中找到唯一匹配的bean进行装配,找不到则抛出异常
2. 如果指定了name,则从上下文中查找名称(id)匹配的bean进行装配,找不到则抛出异常
3. 如果指定了type,则从上下文中找到类型匹配的唯一bean进行装配,找不到或者找到多个,都会抛出异常
4. 如果既没有指定name,又没有指定type,则自动按照byName方式进行装配;如果没有匹配,则回退为一个原始类型进行匹配,如果匹配则自动装配;
推荐使用@Resource注解在字段上,这样就不用写setter方法了.并且这个注解是属于J2EE的,减少了与Spring的耦合,这样代码看起就比较优雅 。
SpringAOP
AOP是什么:AOP它解决了什么问题?项目中哪些地方用到AOP?
在Spring的BeanPostProcessor里完成注入。
OOP实现业务需求,AOP实现系统需求,两者互补。如统一日志监控、统异常一处理。业务中MQ监听统一加注解,通过判断注解来进行切面,解析消息。
AOP是在Spring哪个阶段注入的?
- 在bean后置处理器的
postProcessBeforeInstantiaion方法中,解析切面类,如果bean是切面类,则把通知封装为Advisor,并放入缓存advisordCache中。 - 创建每一个Bean时,在bean后置处理器的
postProcessAfterInitialization中,拿到缓存的所有advisor,根据切入点pontCut与当前bean做匹配,匹配成功则创建动态代理。Bean能够获取到advisor才需要创建代理。如果bean被子类标识为代理,则使用配置的拦截器创建一个代理
$==========AOP框架、源码:如果让你实现一个AOP框架,可以怎么实现?
- 创建描述语言:AOL(Aspect-Oriented-Language),用来描述AOP的概念,以及逻辑。可以自己定义,可以用Java定义。AspectJ就是扩展自Java的AOL。
- 织入:
- 静态织入:第一代AOP。如AspectJ。用ajc编译器预先编译,JVM直接加载Class文件。
- 动态织入:SpringAOP(JVM动态代理,接口)和 AspectJ(整合AspectWerkz框架,子类)。
AOP流程:AOP可以在什么时候织入?如何织入?
- Java代码织入:静态,专用生成工具,EJB,用文件描述,EJB容器根据该描述生成Java类,部署到对应EJB模块。
- 编译期织入:静态,专用编译器。用AOL描述逻辑保存到特定文件,用专用的编译器织入后直接生成字节码。如,AspectJ用ajc编译器。
- 类加载期织入:静态(?),自定义类加载器。用AOL描述逻辑保存到特定文件,在加载class文件的时候改动class,再交给JVM。如JBoss AOP。局限性:如Tomcat等服务器会控制整个类加载体系。
- 程序运行期织入:动态字节码。用CGLIB等Java工具库,代替javac编译器,动态生成字节码,交给JVM运行。需要生成子类,定义为final时没法生成。
- 程序运行期织入:动态代理。Java1.3后原生支持。需要实现接口。Spring默认的代理方式。SpringAOP只对IOC管理的Bean有用。
AOP框架:Spring中AOP包含哪些概念?
- Joinpoint:连接点。具体被切入的执行方法或类等。
- Pointcut:切点。Joinpoint集合,描述要切入到哪些Joinpoint。
- Advice:增强。执行逻辑。
- Aspect:切面。包含多个 Pointcut 和 Advice。
- Weaver:织入器。实现织入功能的对象,对应Spring AOP来说就是ProxyFactory和Cglib。
什么是静态代理?具体代码怎么实现?
工厂模式、静态代理模式。每次使用时用代理类类使用。
@Getter
@Setter
public class SubjectProxy implements ISubject {
@Resource
private ISubject subject; // 注入被代理类,构造方法注入或get/set注入
public String request() {
// 可增加访问前逻辑。增加日志记录等,或者直接拒绝访问等
String originalResult = subject.request();
// 可增加访问后逻辑
return "Proxy:" + originalResult;
}
}
// 使用示例
ISubject target = new SubjectImpl();
ISubject proxy = new SujectProxy(target);
proxy.request();
动态代理?具体代码怎么实现?手动写一个?
关键就是Proxy类和InvocationHandler接口。
Proxy.newProxyInstance(classLoader,targetObj,InvocationHandler)生成动态代理对象。InvocationHandler接口实现invoke(Object proxy, Method method, Object[] args):
// 定义InvocationHandler。增强逻辑:0点到6点期间不让访问
@Slf4j
public class RequestCtrlInvocationHandler implements InvocationHandler {
private Object target;
public RequestCtrlInvocationHandler(Object target) {this.target = target;}
// 增强逻辑写到invoke()方法里
// 参数:代理对象,所有的方法,方法的入参
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
// 只增强request()方法
if (!method.getName.equals("request")) {
return null;
}
// 进行增强
TimeOfDay startTime = new TimeOfDay(0, 0, 0);
TimeOfDay endTime = new TimeOfDay(5, 59, 59);
TimeOfDay currentTime = new TimeOfDay();
if (currentTime.isAfter(startTime) && currentTime.isBefore(endTime)) {
log.warn("Service is not available now!");
return null;
}
return method.invoke(target, args);
}
}
// 使用Proxy代理类动态生成代理对象
public class Demo {
public void demo() {
// 用InvocationHandler增强生成第一个动态代理对象
ISubject subject = (ISubject)Proxy.newProxyInstance(
ProxyRunner.class.getClassLoader(), // 类加载器
new Class[] {ISubject.class}, // 被代理对象实现的接口
new RequestCtrlInvocationHandler(new SubjectImpl)); // InvocationHandler增强
subject.request();
// 用InvocationHandler增强生成第二个动态代理对象
IRequestable requestable = (IRequestable)Proxy.newProxyInstance(
ProxyRunner.class.getClassLoader(),
new Class[] {IRequestable.class},
new RequestCtrlInvocationHandler(new RequestableImpl()));
requestable.request();
}
}
动态字节码生成?具体代码怎么实现?手动写一个?
用enhancer对象设置父类class、callback两个字段后,直接调用enhancer.create()来生成新的代理对象。实现Callback或MethodInterceptor接口的intercept()方法来封装增强。
// 被代理类
public class Requestable{
public void request {
System.out.println("rq in Requestable without implement any interface");
}
}
// 封装增强逻辑到`Callback`或`MethodInterceptor`接口
@Slf4j
public class RequestCtrlCallBack implements MethodInterceptor {
public Object intercept(Object object, Method method, Object[] args, MethodProxy proxy) throws Throwable {
// 只增强request()方法
if (!method.getName.equals("request")) {
return null;
}
// 进行增强
TimeOfDay startTime = new TimeOfDay(0, 0, 0);
TimeOfDay endTime = new TimeOfDay(5, 59, 59);
TimeOfDay currentTime = new TimeOfDay();
if (currentTime.isAfter(startTime) && currentTime.isBefore(endTime)) {
log.warn("Service is not available now!");
return null;
}
return proxy.invokeSuper(object, args);
}
}
// 通过CGLIB的`Enhancer`为目标对象动态生成一个子类,并把`RequestCtrlCallBack`封装的逻辑织入子类
public class Demo {
public void demo() {
Enhancer enhancer = new Enhancer();
enhancer.setSuperClass(Requestable.class);
enhancer.setCallback(new RequestCtrlCallback());
Requestable proxy = (Requestable)enhancer.create();
proxy.request();
}
}
Spring的Joinpoint有哪些连接点?
AOP的JoinPoint可以有很多种类型,例如构造方法调用、字段的设置及获取、方法调用、方法执行等。SpringAOP只支持方法执行。
Spring的PointCut源码怎么设计的?哪些接口哪些类?
PointCut接口:
// PointCut接口定义
public interface Pointcut {
ClassFilter getClassFilter(); // 类型匹配。在哪些类生效
MethodMatcher getMethodMatcher(); // 方法匹配。在哪些方法生效
Pointcut TRUE = TruePointcut.INSTANCE; // 不进行过滤,全部方法都生效
}
// ClassFilter接口定义
public interface ClassFilter {
boolean matches(Class clazz); // 返回true时匹配
ClassFilter TRUE = TureClassFilter.INSTANCE; // 所有对象都匹配
}
// MethodMetcher接口定义
public interface MethodMetcher {
boolean isRuntime(); // 是否需要参考执行时信息。决定使用静态还是动态匹配
boolean matches(Method method, Class targetClass); // 静态方法匹配,无需检测方法入参
boolean matches(Method method, Class tartgetClass, Object[] args); // 动态方法匹配。涉及到了方法入参。先执行静态,匹配后再执行动态。只针对具体的入参,所以不缓存到框架。
MethodMetcher TRUE = TrueMethodMatcher.INSTANCE; // 和上面的匹配所有对象一样的用法
}
根据MethodMatcher类型,**Pointcut就可以分为两类,即StaticMethodMetcherPointcut和DynamicMethodMatcherPointcut**。它们继承了Pointcut和MethodMatcher两个接口。
整体设计如下,再加上注解匹配AnnotationMatchingPointcut、以及相互计算的、自定义的等:

自定义的Pointcut,实现StaticMethodMarcherPointcut和DynamicMethodMatcherPointcut即可,重写match(Method method, Class clazz)或match(Method method, Class clazz, Object[] args)方法。
Spring中的Pointcut实现都是普通对象,所以我们都可以通过IOC容器来注册使用它们。不过一般不这样玩。
Spring的Advice源码怎么设计的?哪些接口哪些类?
Spring AOP加入了开源组织AOP Alliance,所以Spring中的Advice全部遵循AOP Alliance规定的接口。
在Spring中,Advice按照它自身的对象是否能在目标对象类的所有实例中共享,分为了per-class和per-instance两大类。即类级别和对象级别:
类级别:不保留增强目标对象的信息。最常用的:

对象级别:唯一的一种per-instance型Advice,Introdution类型。对象定制的,会保存不同实例对象的状态和相关逻辑,可以在不改动目标类定义的情况下,为目标类添加新的属性和行为。
IntroductionInterceptor的Advice分为两个分支,以IntroductionInfo静态可配置分支和DynamicIntroductionAdvice动态分支:

Spring的Aspect源码怎么设计的?哪些接口哪些类?
Aspect用来装Pointcut和Advice。Spring中的Aspect实现是Advisor。它和标准的Aspect有所不同。标准的Aspect定义中可以有多个Pointcut和多个Advice。但是Advisor一般只有一个Pointcut和一个Advice。我们可以认为Advisor是一种特殊的Aspect。
Advisor的实现结构体系可以简单的分为两个分支,PontcutAdvisor和IntroductionAdvisor:

PontcutAdvisor:

IntroductionAdvisor,只能应用于类级别的拦截,只能使用Introduction型的Advice。为Introduction定制的:

Ordered:多个Advisor的Pointcut匹配到同一个Joinpoint时,默认按Advisor声明的先后顺序执行。另外各个Advisor都实现了Ordered接口。order越小,执行顺序越靠前、越优先,即越位于AOP的外侧。
Spring的AOP织入怎么设计的?哪些接口哪些类?
Spring AOP中,默认使用代理ProxyFactory作为织入器,同时支持动态代理和CGLIB。
使用示例:
// 第一步,提供目标对象
ProxyFactory weaver = new ProxyFactory(yourTargetObject);
// 第二步,提供advisor
Advisor advisor = ...;
weaver.addAdvisor(advisor);
// 第三步,织入。获取代理对象。
Object proxyObject = weaver.getProxy();
// 现在proxyObject可以使用啦...
// 另外,可以给ProxyFactory指定Advice。除了Introduction类型,它会内部自动生成Advisor。
// 对于`Introduction`类型的`Advice`,a.如果是*Introductionlnfo的子类*,则构造一个*DefaultIntroductionAdvisor*(因为共用)。b.如果是*DynamicIntroductionAdvice的子类*,框架内部将抛出*AopConfigException异常*(因为无法取得必要的目标对象信息)。
// 也可以设置属性,来选择用类代理还是接口代理。不设置时,按默认值来。
Spring事务
Spring事务传播行为?
在TransactionDefinition接口中定义了7个表示事务传播行为的常量。
支持当前事务的情况:
- PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)。
不支持当前事务的情况:
- PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
- PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED。
$==========事务如何实现?框架?初始化流程?
- 在bean后置处理器的postProcessBeforeInstantiaion方法中,解析切面类,如果bean是切面类,则把通知封装为Advisor,并放入缓存advisordCache中。
- 创建每一个Bean时,在bean后置处理器的postProcessAfterInitialization中,拿到缓存的所有advisor,根据切入点pontCut与当前bean做匹配,匹配成功则创建动态代理。Bean能够获取到advisor才需要创建代理。
SpringMVC
整体架构?
$==========整体访问流程?
- HandlerMapping
- HandlerAdapter
- Handler
- 视图解析
- 视图渲染
初始化流程?
MyBatis
¥==========。。。整体架构?整体访问流程?
一级缓存、二级缓存?
Mapper原理?
插件?
SpringBoot
解决什么问题?
自动配置原理?自定义配置原理?
@SpringBootApplication
@EnableAutoConfiguration@Import(AutoConfigurationImportSelector.class):*AutoConfigurationImportSelector.class会默认加载MATE-INF/spring.factories,以及好多自动配置类*@AutoConfigurationPackage@Import(AutoConfigurationPackages.Registrar.class):*AutoConfigurationPackages.Registrar.class会去加载启动类所在包下面的所有类*
@SpringBootConfiguration(本质上是@Configuration注解,随意包装改名了一下)
启动流程?
待看:https://cloud.tencent.com/developer/article/1761068
- 创建 ApplicationArguments 对象初始化默认应用参数类。args是启动Spring应用的命令行参数,该参数可以在Spring应用中被访问。如:–server.port=9000
- 项目运行环境Environment的预配置:并遍历调用所有的SpringApplicationRunListener的environmentPrepared()方法,并过滤掉不要的env。
- 创建Spring容器:根据 webApplicationType 进行判断,确定容器类型。
- Spring容器前置处理(BeanDefinition?):容器刷新之前的准备动作。包含一个非常关键的操作:将启动类注入容器,为后续开启自动化配置奠定基础。
- 容器初始化:开启(刷新)Spring 容器,通过refresh方法对整个IoC容器的初始化。
- Spring容器后置处理:扩展接口,设计模式中的模板方法,默认为空实现。afterRefresh(context, applicationArguments);
- 发出结束执行的事件:listeners.started(context);
- 执行Runners :用于调用项目中自定义的执行器XxxRunner类,使得在项目启动完成后立即执行一些特定程序
- 发布应用上下文就绪事件
Spring Boot启动流程
- 首先从main找到run()方法,在执行run()方法之前new一个SpringApplication对象
- 进入run()方法,创建应用监听器SpringApplicationRunListeners开始监听
- 然后加载SpringBoot配置环境(ConfigurableEnvironment),然后把配置环境(Environment)加入监听对象中
- 然后加载应用上下文(ConfigurableApplicationContext),当做run方法的返回对象
- 最后创建Spring容器,refreshContext(context),实现starter自动化配置和bean的实例化等工作。
SpringBoot自动装配
- 通过
@EnableAutoConfiguration注解在类路径的META-INF/spring.factories文件中找到所有的对应配置类,然后将这些自动配置类加载到spring容器中
内嵌Tomcat原理?
总体逻辑:
spring-boot-autoconfigure.jar下的/META-INF/spring.factories文件引入ServletWebServerFactoryAutoConfiguration自动配置类。ServletWebServerFactoryAutoConfiguration自动配置类引入ServletWebServerFactoryAutoConfiguration.EmbeddedTomcat配置类EmbeddedTomcat配置类向Spring容器注入TomcatServletWebServerFactory- Spring执行
refresh()方法,bean定义注入容器中后,执行onRefresh()方法(空方法,由子类实现),之后执行普通单例bean的实例化和初始化。 - web容器继承类
ServletWebServerApplicationContext执行onRefresh()方法,调用到了createWebServer()方法来创建web服务器。 createWebServer()方法通过之前配置的ServletWebServerFactory,获取webServer,即创建web服务器。
SpringCloud
Eureka原理?整体架构?高可用配置?如何通信?
一级只读缓存(30s更新一次) -> 二级读写缓存(180s更新一次) -> 数据存储层(concurrentHashMap)。
各级缓存同步方式和DB/Redis类似,先改底层,再删缓存。
我们可以缩短只读缓存的更新时间 (eureka.server.response-cache-update-interval-ms)让服务发现变得更加及时,或者直接将只读缓存关闭(eureka.server.use-read-only-response-cache=false),多级缓存也导致Client层面(数据一致性)很薄弱。
Gateway原理?整体架构?高可用配置?路由?限流、降级、熔断怎么做?鉴权?
OpenFeign原理?源码分析?
- @EnableFeignClients开启扫描所有@FeignClient注解的接口,将所有的访问路径以及接口信息封装成一个FeignClientFactoryBean注册到Spring容器中。
- 动态代理Target ->
- 解析注解规则解析出底层methodHandler:结果是一个
List<Methoddata>-> - 构造Http Request 对象:基于RequestBean动态生成Request:根据传入的Bean对象和注解信息,从中提取出相应的值,来构造Http Request 对象 -》
- 编码:Encoder将Bean包装成请求 -》
- 拦截器:对请求返回做装饰处理,用于用户自定义对请求的操作,比如,如果希望Http消息传递过程中被压缩,可以定义一个请求拦截器。 -》
- 日志:Feign定义了统一的日志门面来输出日志信息 , 并且将日志的输出定义了四个等级:NONE、BASIC、HEADERS、FULL -》
- http调用:基于重试器调用http框架处理
Feign 默认底层通过JDK 的 java.net.HttpURLConnection 实现了feign.Client接口类,在每次发送请求的时候,都会创建新的HttpURLConnection 链接,这也就是为什么默认情况下Feign的性能很差的原因。可以通过拓展该接口,使用Apache HttpClient 或者OkHttp3等基于连接池的高性能Http客户端。
而这个client会委托给org.springframework.cloud.openfeign.ribbon.LoadBalancerFeignClient进行负载均衡地调用,采用了观察者模式。
Hystrix原理?整体架构?
线程池/信号量4种信号(excute/future/observ/toObserv)-> 缓存(请求缓存/合并)-> 断路器 -> 线程池/信号量已满 -> 正常业务(成功/失败/未响应) -> 重新计算断路器状态 -> 返回四种方式执行。
断路器断开 -> sleep -> 半闭合 -> 断开或闭合。
断路器状态用滚筒式维护,每秒一组记录,记录成功/失败/未响应/拒绝数量。
Rpc原理?
编码/序列化,发送,接受,解码/序列化。参见openFeign。
分布式
$==========分布式锁?DB?SetNx?Relock?ZK?
常见方案:
基于数据库实现分布式锁
- 基于数据库表(锁表,很少使用):加锁:直接插入一条记录。Key可以直接作为主键。释放锁:删除记录。
- 乐观锁(基于版本号)
- 悲观锁(基于排它锁)
基于 redis 实现分布式锁:
- 单个Redis实例:setnx(key,当前时间+过期时间) + Lua
- Redis集群模式:Redlock:
- 依次轮询加锁.
- 每次问询有过期时间,超时立马下一个。
- 获取节点大于N,且锁有效时间(总时间-询问时间)>0,锁有效。
- 主从问题:
- 主从切换时,可能导致同时获得锁:主的锁数据没有同步到从。 -> Redlock解决。
- 锁超时问题:此时不知道A的锁还有没有被占用,B已经可以拿到锁了。-> Redlock解决。
- 数据淘汰:锁被淘汰了?
- RedLock问题:
- 脑裂丢锁,节点切换时:节点1从ABC获取锁成功,C挂了,数据还未能持久化,C起来了,节点2从CDE获得了锁。AOF默认是每秒保存一次。即使改为每次提交都fsync,但是还是没法保证一定能存下来。解决方案:延迟重启。C挂掉后,经历大于锁的有效时间后,再重启。
- 超时问题仍然未能解决,redission是搞了一个看门狗去延时。
- 时间跳跃问题:Redlock算法对时钟依赖性太强, 若N个节点中的某个节点发生 时间跳跃,则也有可能出大问题。
- 释放锁时要发送到全部节点。防止之前有未响应节点的情况。
Redission实现方式:
- redisson所有指令都通过lua脚本执行,保证了操作的原子性
- redisson设置了watchdog看门狗,“看门狗”的逻辑保证了没有死锁发生
- redisson支持Redlock的实现方式。
基于 zookeeper实现分布式锁
- 临时有序节点来实现的分布式锁,Curator
- 与Redis相比
- 没有自旋锁:当获取锁被拒绝后,无需不断的循环。
- 没有锁超时问题,服务下线,ZK会自动剔除临时节点。
- 不过性能稍弱,但还好。
如果有客户端 1、客户端 2 等 N 个客户端争抢一个 ZooKeeper 分布式锁。大致如下:
- 大家都是上来直接创建一个锁节点下的一个接一个的临时有序节点;
- 如果自己不是第一个节点,就对自己上一个节点加监听器;
- 只要上一个节点释放锁,自己就排到前面去了,相当于是一个排队机制。
而且用临时顺序节点的另外一个用意就是,如果某个客户端创建临时顺序节点之后,不小心自己宕机了也没关系。ZooKeeper 感知到那个客户端宕机,会自动删除对应的临时顺序节点,相当于自动释放锁,或者是自动取消自己的排队。
基于 Consul 实现分布式锁
$==========分布式事务?
参照:
https://pdai.tech/md/arch/arch-z-transection.html#%E4%B8%A4%E6%AE%B5%E6%8F%90%E4%BA%A42pc
XA协议:基于数据库的分布式事务协议。分为两部分:事务管理器 Transaction Manager和 本地资源管理器 Resource Manager。MySQL实现了接口。
- 2PC:数据库层面。现实中很少用。
- 业务逻辑:
- 投票阶段prepare:协调者问大家是否都准备好提交了。此时参与者已经执行完事务,就等提交。有人no就abort。
- 执行阶段commit:协调者让大家提交或回滚。协调者完成提交或回滚操作后,向协调者发送DONE消息以确认。
- 坑:
- 网络抖动造成数据一致性问题:第二阶段叫大家提交,结果网络抖动,造成一部分节点接收到commit消息提交,另外一部分则没有。
- 超时导致阻塞问题:2PC所有参与者都是为事务阻塞型的,只要有一个参与者超时,其他所有参与者都会等待。
- 单点故障:协调者挂了,就全阻塞了。例如,协调者A执行第一阶段,所有参与者等着,协调者A挂掉,重新选择协调者B上来,所有参与者都会阻塞。
- 业务逻辑:
- 3PC:在2PC的基础上插入了一个准备阶段,并加入超时机制。
- 业务逻辑:
- 投票阶段CanCommit:协调者问大家是否可以执行事务操作。有人no就abort。
- 准备阶段PreCommit:协调者问大家是否可以进行事务预提交操作。有人no就abort。
- 执行阶段DoCommit:协调者让大家正式提交事务。有人no就abort。
- 比2PC改进项:
- 加入一个准备阶段:保证了在最后提交阶段之前,各参与者节点的状态都一致。3PC将2PC的提交事务请求分成了CanCommit以及PreCommit。
- 引入超时机制,解决协调者的单点故障问题:参与者各种原因未收到协调者的commit请求时,会自己进行提交。2PC只有协调者有超时,3PC协调者参与者都有超时。
- 坑
- 没有完美解决2PC的阻塞问题:阻塞是相对的,存在协调者和参与者同时失败的情形下, 3PC事务依然会阻塞。
- 也引入了新的问题(不一致问题):
- 业务逻辑:
- 个人思考
- 为啥又要加入一个新的阶段:避免超时又回滚。例如,2PC的情况下,协调者向大家发送prepare指令,即使A未响应,BCD仍然会执行事务的重量级操作。而提前问一下,那么就能提前识别这种未响应的问题,避免的执行事务重量级操作。简单来说,canCommit阶段就是做了一次超时校验。
- 2PC:数据库层面。现实中很少用。
基于补偿业务
- TCC:
- 业务逻辑:和2PC很像。TCC是在业务层,2PC是在DB层。通过编写业务来实现业务层的2PC。
- Try阶段:下单时通过Try操作去扣除库存预留资源。
- Confirm阶段:确认执行业务操作,在只预留的资源基础上,发起购买请求。
- Cancel阶段:只要涉及到的相关业务中,有一个业务方预留资源未成功,则取消所有业务资源的预留请求。
- 坑:需要分支事务表的支持。Seata有提供该事务表。
- 空回滚:协调者同时向ABC发送try,B未响应,协调者通知ABC回滚,B重启后收到回滚命令。此时造成了空回滚。解决方案:try执行时创建全局事务ID,和分支事务ID一起存入分支事务表中。回滚时查找有没有try的执行记录。
- 幂等问题:网络不稳定,为了保证执行,会加入重试机制。此时就要保证cancel和confirm是幂等的。解决方案:在分支事务记录表中增加事务执行状态即可。
- 悬挂问题:向A发送try,超时了,再向A发送cancel,执行了。之后try请求又到了,此时资源就被占用悬挂,无法释放。解决方案:同样借助分支事务表中事务的执行状态。如果已经执行了confirm或者cancel那么try就执行。
- 业务逻辑:和2PC很像。TCC是在业务层,2PC是在DB层。通过编写业务来实现业务层的2PC。
- SAGA:
- 业务逻辑:
- 由一系列的本地事务构成。
- 一个事务执行完毕后,基于事件的方式,或者基于命令的方式,触发后续的本地事务执行。
- 基于事件方式:按照监听各自触发。自己监听其它服务产生的事件,并决定是否需要针对监听到的事件做出响应。
- 基于命令方式:有一个统一的协调者。协调中心来告诉Saga的参与方应该执行哪一个本地事务。
- 执行失败时,回滚该本地事务之前的所有本地事务操作。
- 业务逻辑:
- TCC:
基于最终一致性
- 本地消息表:
- 处理逻辑:核心思路是将分布式事务拆分成本地事务进行处理。
- 事务主动方:在同一个本地事务中处理业务和写消息表操作
- 事务主动方 -> 消息中间件,通知事务被动方处理事务通知事务待消息。
- 消息中间件 -> 事务消费方:事务消费方消费并处理消息队列中的消息。
- 消息中间件 <- 事务消费方:事务被动方通过消息中间件,通知事务主动方事务已处理的消息。
- 事务主动方 <- 消息中间件:事务主动方接收中间件的消息,更新消息表的状态为已处理。
- 缺点:
- 与具体的业务场景绑定,耦合性强,不可公用。
- 并发度不高:消息数据与业务数据同库,占用业务系统资源。
- 处理逻辑:核心思路是将分布式事务拆分成本地事务进行处理。
- 可靠消息队列:其实是对本地消息表的封装,将本地消息表封装到 MQ 内部,其他方面的协议基本与本地消息表一致。关键字:半消息。回查。
- 业务流程,正常情况:
- 发送方向 MQ 服务端(MQ Server)发送 half 消息。
- MQ Server 将消息持久化成功之后,向发送方 ack 确认消息已经发送成功。
- 发送方开始执行本地事务逻辑。
- 发送方根据本地事务执行结果向 MQ Server 提交二次确认(commit 或是 rollback)。
- MQ Server 收到 commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;MQ Server 收到 rollback 状态则删除半消息,订阅方将不接受该消息。
- 业务流程,异常情况:
- MQ Server 对该消息发起消息回查。
- 发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 发送方根据检查得到的本地事务的最终状态再次提交二次确认。
- MQ Server基于 commit/rollback 对消息进行投递或者删除。
- 优点:
- 消息数据独立存储 ,降低业务系统与消息系统之间的耦合。
- 吞吐量大于使用本地消息表方案。
- 缺点:
- 一次消息发送需要两次网络请求(half 消息 + commit/rollback 消息) 。
- 业务处理服务需要实现消息状态回查接口。
- 业务流程,正常情况:
- 最大努力通知:也称为定期校对,是对MQ事务方案的进一步优化。在事务主动方增加了消息校对的接口,如果事务被动方没有接收到消息,可调接口主动查询。
- 本地消息表:
分布式ID?雪花算法?
1 + 41 + 10 + 12。极度依赖时间序列,即时钟稳定性。
限流算法?令牌桶、漏桶、计数器、滑动窗口
- 令牌桶:Guava有包
- 漏桶:redisTemplet.opszset.add。访问进来时,++water向集合放入一个元素。然后以时间为socore进行排序,取一段时间内的元素数量,进行比较。
- 计数器:redis
- 滑动窗口:redis。list,过期时间,计数。
=========== Paxos算法?Raft算法?ZAB算法?
CAP原理?Base?
分布式数据库?
XXL定时任务?
设计模式
常用设计模式?在Spring等中的体现?
- SpringMvc 责任链
- 工厂
- 代理
- servlet:模板
- 单例
单例模式?
- 饿汉式
- 懒汉式
- 双检锁
- 枚举
各个原则?
- S:单一职责。
- O:开闭原则。“对扩展开放、修改关闭”。
- L:里氏代换。子类可替代父类。跟多态不同的是,子类不会改变父类的行为。
- I:接口隔离。不依赖不需要的接口。例如将函数或类拆为更细粒度的接口。单一职责侧重于接口设计,接口隔离则从调用者角度考虑
- D:依赖反转。控制权由程序员交给系统。
贫血模型?DDD领域设计?
原来的VO只是一个数据结构。现在是把service里通用的业务逻辑抽到VO里,VO作为一个可复用的业务中间层。
算法
分布式共识算法?
海量数据算法?找出Top10?
八大排序算法?桶排序?基数排序?
手写归并排序?
快速排序?
二分查找?
二叉树遍历?
二叉树层序遍历?
实现堆?
实现栈?
反转链表?
其他算法?链表、二叉树、动态规划?
红黑树?KMP?
哈希表?
场景设计题
用读写锁实现一个Cathe缓存工具类
实现一个生产者-消费者队列?
10亿红包派发?阿里云
设计一个秒杀系统?阿里云
项目亮点
项目QPS?TPS?整体架构?
TPS上万并发就几十万了。一般上万QPS,TPS就几百。
根据简历亮点提问?你觉得做得最好的项目?最有挑战的地方?
选型:为什么要用这种方案?
实战:有哪些参数要注意?如何监控?如何调优?如何排查问题?
哪些地方还可以改进?如果流量/数据量扩大100倍怎么处理?
计算机网络/安全
Http?常用字段?Https?1.0、1.1、2.0、3.0?常见状态码?
- HTTP 1.0:每次发送请求都是一个新请求,要重新建立tcp请求,不允许断点续传
- HTTP 1.1:长连接,缓存管理(304)、断点续传
- HTTP 2.0:多路复用,一个tcp连接能够处理多个http请求,服务器推送(Sever push),头部压缩和索引表,
- HTTP 3.0:基于google的QUIC协议,而quic协议是使用udp实现的。解决了http 2.0中前一个stream丢包导致后一个stream被阻塞的问题。
$==========Https?
- 两边相互交换随机数和加密套路
- 服务端把证书给客户端
- 客户端用证书里的公钥,加密一个随机数pre-master,发送给服务端
- 两边同时用3个随机数算出对称加密秘钥
- 两边相互提议用对称加密
- 两边相互用对称加密握手验证
$==========TCP?三次握手四次挥手?拥塞控制?滑动窗口?
TCP与UDP区别?
- 无连接,不维护连接状态。消息可能丢失,可能乱序到达。
- 字节流/数据包
- 没有拥塞控制
- 无状态。只管发,发出去后就不管。不会记着有没有发、又没有收到、发到哪个了、收到哪个了。
IP协议?
Linux五种IO模型?阻塞非阻塞?同步异步?5种模型?select、poll、epoll区别?
https://www.pdai.tech/md/interview/x-interview.html#42-5%E7%A7%8Dio%E6%A8%A1%E5%9E%8B

其他常用协议?
加密算法?
- 摘要算法:MD5算法、SHA-1算法
- 对称加密:数据加密标准(DES,Data Encryption Standard)算法
- 非对称加密:RSA(Rivest Shamir Adleman)算法
操作系统
进程和线程有啥区别?
进程间通信方式?
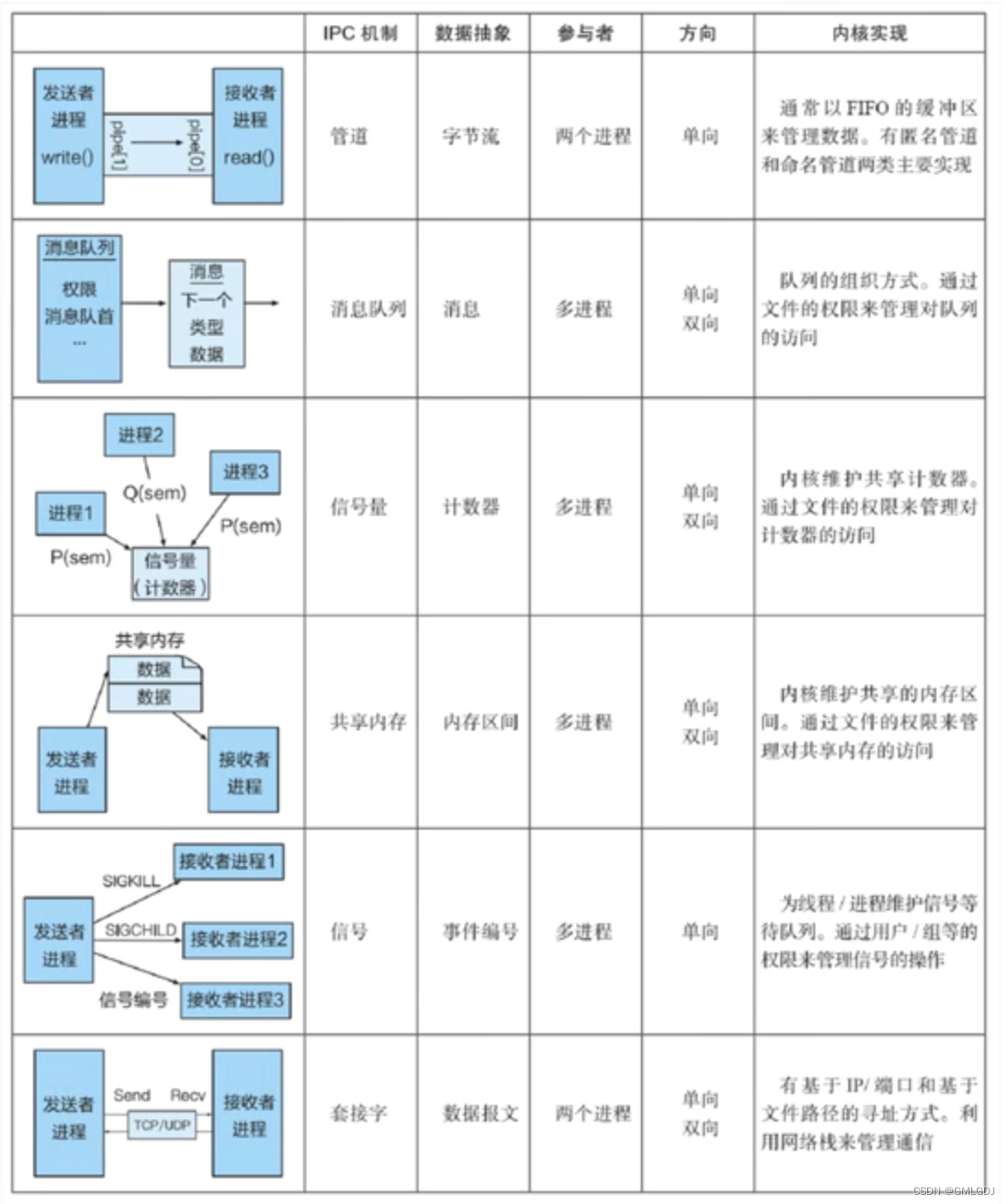
零拷贝?
Linux
常用监控及查看命令?网口、端口、进程、日志?
pdai:
著作权归https://pdai.tech所有。 链接:https://www.pdai.tech/md/interview/x-interview.html
文本操作
- 文本查找 - grep
- 文本分析 - awk
- 文本处理 - sed
文件操作
- 文件监听 - tail
- 文件查找 - find
网络和进程
- 网络接口 - ifconfig
- 防火墙 - iptables -L
- 路由表 - route -n
- netstat
其它常用
- 进程 ps -ef | grep java
- 分区大小 dh -f
- 内存 free -m
- 硬盘大小 fdisk -l |grep Disk
- top
- 环境变量 env
CPU:top命令
- load average:进程队列的长度,经验值0.7以下。
- 进程消耗的 CPU 时间百分比,IO占比等:%Cpu(s): 3.9 us, 1.3 sy, 0.0 ni, 94.6 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
- 1: CPU 的各核数和每个核的运行状态
内存: free命令
- 内存空间会开辟 buffer 和 cache 缓冲区。
- available :能体现出缓冲区可用内存的大小,这个指标可以比较真实地反映出内存是否达到使用上限
磁盘:iostat命令
- idle 代表磁盘空闲百分比;
- util 接近 100%,表示磁盘产生的 I/O 请求太多,I/O 系统已经满负荷在工作,该磁盘可能存在瓶颈;
- svctm 代表平均每次设备 I/O 操作的服务时间 (毫秒)。
- 如果 idle 长期在 50% 以下,util 值在 50% 以上以及 svctm 高于 10ms,说明磁盘可能存在一定的问题。接着我会定位到具体是哪个进程造成的磁盘瓶颈,下面我就为你介绍一个关于定位的命令。
- iotop命令:这个命令并不是 linux 原生的,需要安装,以 CentOS 7.0 为例:
yum -y install iotop。然后就可以看到哪个进程在消耗资源。
网络:netstat命令:提供 TCP 和 UDP 的连接状态等统计信息,可以简单判断网络是否存在堵塞。
- recv-Q:网络接收队列还有多少请求在排队。
- send-Q:网络发送队列有多少请求在排队。
- recv-Q 和 send-Q 如果长期不为 0,很可能存在网络拥堵,这个是判断网络瓶颈的重要依据。
- Foreign Address:与本机端口通信的外部 socket。
- State:TCP 的连接状态。
Nginx
负载均衡怎么配置?
Tomcat
整体架构?
Docker
docker原理?
怎么建一个Dockfile?
K8s
K8s原理?整体架构?
智商测试题/行测题
参照公务员行测考试
职业发展等其他问题
- 最近在看什么书?在看什么开源项目?
- 怎么学习一项新技术?
- 管理方面有什么方法论?和下级、同级、上级怎么相处?开发任务重怎么办?
- 为什么离职?
- 之后几年有什么计划?
- 期望薪资多少?
通用提问
回答问题的几个归纳维度:
- 性能问题:硬件、软件、参数
- 系统项目设计:性能、可用性、扩展性
- 突发事件处理:事前、事中、事后
通用提问:
- 中间件:
- 如何选型?选哪个版本?
- 整体设计思路?
- 某个基础操作的整个执行流程?
- 线上指标监控?
- 线上问题排查?
- 核心参数配置?
- 查看日志?
- 宕机未响应怎么办?
- 其他最佳实践?
- 热点问题?数据偏斜问题?平滑切换问题?未响应问题?数据一致性问题(主从、缓存)?
- 框架设计方法论:我要完成什么功能?基于此我要设计什么数据结构或基础设施?我需要哪些操作方法?
- 场景设计题
分布式节点通用思考问题:
- 单机
- 高性能:
- 整体架构设计
- 基本语句执行流程
- 如何优化?有哪些地方或参数是性能瓶颈?
- 如何确定基线性能?
- 如何检测线上性能?
- 线上执行很慢,什么问题?
- 线上如何监控运行情况?资源满了怎么办?突然CPU彪升、内存满了、磁盘满了、网卡/网络连接数满了怎么办?当场怎么处理?之后怎么排查错误?怎么看日志?事前怎么预防?事后怎么改进?
- 线上高性能参数如何配置?
- 如何解决热点问题?
- 如何解决数据偏斜问题?
- 高可用:
- 如何持久化?整体流程?有哪些持久化策略?
- 持久化时,有新数据写入怎么办?如果是两阶段日志,如何保证新老日志数据相同?写时复制?
- 持久化时,突然宕机怎么办?日志还完整吗?
- 宕机时,如何保证数据不丢?
- 重启后,数据如何恢复?恢复流程?
- 线上高可用参数如何配置?
- 线上如何监控运行情况?资源满了怎么办?突然CPU彪升、内存满了、磁盘满了、网卡/网络连接数满了怎么办?宕机、死锁、未响应怎么办?当场怎么处理?之后怎么排查错误?怎么看日志?事前怎么预防?事后怎么改进?
- 有哪些日志?
- 可扩展:
- 哪些地方是性能瓶颈?如果此时流量/数据量大幅提升,可以如何扩展?
- 使用的版本?都有啥区别?
- 和其他同类中间件的区别?选型依据?
- 高性能:
- 主从:
- 高性能:
- 数据如何同步?第一次如何同步?后续如何同步?
- 怎么解决数据不一致问题?从没有主快?从的数据不是最新的?
- 如何检测线上性能?
- 线上高性能参数如何配置?
- 高可用:
- 同步数据在主和从是怎么做持久化的?
- 持久化时,有新的数据写入怎么办?如何解决主从数据不一致问题?
- 主故障,如何切换?如何选主?如何保证数据不丢?
- 主故障后,如何保证从的数据是最新的?
- 主重启后,数据如何恢复?
- 主重启后,如何重新加入集群?
- 从故障,数据如何做持久化?如何保证数据不丢?
- 从重启后,数据如何恢复?
- 从重启后,如何重新加入集群?
- 网络波动,主未响应,造成脑裂问题,如何预防或处理?
- 网络波动,从未响应,如何处理?
- 线上高可用参数设置?
- 线上如何监控运行情况?出错了怎么看日志?怎么排查日志和错误?
- 可扩展:
- 数据分布策略?节点部署方式?
- 怎么加子节点?数据如何平滑迁移?
- 怎么删子节点?数据如何平滑迁移?
- 高性能:
- 通用问题:
- 网络波动,导致超时怎么办?
- 调用未响应怎么办?
- 顺序性问题:未响应后判断它已经失败,结果之前的命令又过来了?如TCC。
- 其他线程/资源同时过来调用,怎么处理?
- 调用慢怎么办?
- 假死怎么办?
- 数据一致性问题?
后续提升目标
- 英语:每天25单词
- 算法:每天1题
- 设计模式:融入到代码中
- 场景设计题:每周1道
- OS / Linux / 网络 / 计组
- 管理方法论:各种书籍+实践
- 身体健康:每周健身2h
- IO / Netty 源码 / lua
- SpringAlibaba技术栈
- Gateway
- Nacos
- Dubbo
- Setenal
- Seata
- RocketMQ / Kafka 源码
- ES / MangoDB / ZK 源码
- 压测/QPS/TPS/PV/RT等
我的IT技术路摘录
序列化、反射、拷贝
Java创建一个类的方法有几种?
Java的序列化的作用是什么?
序列化其底层实现的原理是如何的?ObjectOutPutStream。
#你了解到哪些常见的序列化框架,其优缺点是?
Java 序列化类中有一个final的Long型id,这个序列化id的作用是什么?如果没有的话,是否可以序列化成功?
如果不想序列化某个字段,应该怎么办?
聊聊你对java拷贝的认识?什么是深拷贝,什么是浅拷贝?
怎么实现一个java 的深拷贝?
介绍一下你了解的反射,反射的原理是什么?
怎么实现一个反射?反射的几种调用方法?区别是什么?
字符串
1. public static void main(String[] args) {
2. String s1 = new String("abc");
3. String s2 = "abc";
4. String s3 = new String("abc");
5. String s4 = "abc";
6. String s5 = "a"+"bc";
7. String s6 = new String("a")+"bc";
8. System.out.println(s1 == s2); //false
9. System.out.println(s1.equals(s2)); //true
10. System.out.println(s1 == s3); //false
11. System.out.println(s2 == s3); //false
12. System.out.println(s2 == s4); //true
13. System.out.println(s2 == s5); //true
14. System.out.println(s2 == s6); //false
15. System.out.println(s1 == s1.intern()); //false
16. System.out.println(s2 == s1.intern()); //true
17. System.out.println(s2 == s2.intern()); //true
18. System.out.println(s1.intern() == s3.intern()); //true
19. }
Java中== 和equals的区别是什么?
#jvm的内存模型?各版本字符串常量池在哪?
字符串的intern方法作用?
字符串是一定不能修改的么?一定要改的话用反射。
说明一下StringBuilder、StringBuffer和String的区别?
Java中 hashCode 和 equals方法的区别?
继承,static关键字(校招问的较多)
Java的构造函数能不能重写?私有方法可以被重写么?
说说你了解到的static关键字的用法?为什么static方法中不能使用this关键字?静态内部类的作用是什么?
接口和抽象类的区别是什么?
异常(问到的概率不太大)
请简单介绍JAVA的异常类?运行时异常和受检异常的区别是什么?Error和Exception的区别是什么?
举例说说你平时碰到的Error和Exception?
NoClassDefFoundError 和ClassNotFoundException 的区别是什么?
Throw和Throws的区别是什么?
final、finally、finalize的区别是什么?
一般在实际项目中,有哪些处理异常的方法,说说你的理解?
泛型、注解(只是有可能面试到)
泛型的工作原理?有了解过类型擦除么?
泛型的原型
泛型的优缺点
擦除之后,如何获取类型?
泛型的限定符
如何定义一个java的注解,并阐述其实现原理
IO(面试出现频率较高)有点云里雾里
##能简单说明一下你了解的网络IO模型么?阻塞IO,非阻塞IO,IO多路复用(select、poll、epoll),信号驱动,异步IO。
Unix网络编程中描述的5种网络io模型
io多路复用的select、poll、epoll的区别是什么?每次传表线性遍历限制1024,每次传表线性遍历无长度限制,穿一次表OS回调机制
Epoll的两种触发方式有什么区别?只触发一次,每次都触发。
有了解过reactor和proactor模型么?
说说你对java整个io包的理解,java在设计io的时候使用了哪两种设计模式?
NIO的三大组件了解么?说说channel和stream的区别?
集合
能简单说明一下你了解的集合么?
#说说ArrayList、linkedlist、vector的区别?ArrayList增删调的的系统函数整体移动1位,所以复杂度也为O(1).
说说hashset和treeset的区别?
#如何在循环中安全的删除一个ArrayList的数据?1.8之前,迭代器。1.8后:list2.removeIf(s -> s.equals("1"))。底层是迭代器。
说说你理解的fail-fast和fail-safe?
说说ArrayList的扩容机制?直接1.5倍,然后保证在最小最大区间内。
说说hashset是怎么保证元素唯一的?底层是hashmap,判断hash和equals都相等。
comparable 和 Comparator 的区别是什么?前者是内部实现比较方法的接口。后者是外部封装比较方法的接口。
##说下HashMap的put和get流程?hash()分配桶->容器为空否->头结点为空否->头结点是红黑树否->链表->扩容
说说hashMap的hash函数的实现?
说说hashMap的扩容过程?啥时候会发生扩容?
说说hashMap的数据结构?
说说hashMap中使用红黑树的作用?为什么不一直使用红黑树?什么时候进行转换?
用最简单的语言描述下红黑树,以及其涉及的三个操作,换色,左旋和右旋?
hashMap、hashtable和concurrentHashMap的区别?
Hashmap、treemap、linkedhashmap的区别?
#设计实现一个LRU?LFU?重写linkedhashmap的removeEldestEntry()方法即可。默认是返回false不删除。
多线程
说下并发和并行的区别?
说下线程和进程的区别?了解过守护线程么?
多线程的三个基本特性是什么?Java 怎么解决的?有序性、可见性、原子性。编译、缓存优化,共享。volitale,先行发生,锁/无锁、死锁
线程的状态有哪些?它们是怎么转换的?Jvm使用什么指令查看线程状态?
简述一下JMM,as-if-serial语义,happens-before模型?
了解过死锁么?解决死锁的方法有哪些?
CAS了解过么?
缓存一致性协议了解么?更新共享变量时,发消息给其他CPU,让它们把自己的副本置为无效。下次要用时,再来存取。
了解volatile关键字么?作用是什么?能否保证线程安全?
了解synchronized关键字么?什么是锁升级?Synchronized的三种使用方式?synchronized锁住的静态方法和非静态方法的区别是什么?
写一个线程安全的单例?
了解java的ReentrantLock么?它和synchronized的区别是什么?
AQS的源码有了解过么?说说公平锁加锁过程和释放锁的过程?为什么公平锁的性能要低于非公平锁?共享锁和非共享锁的区别是什么?可重入和不可重入的区别是什么?
Java如何创建多线程?Thread的run方法和start方法的区别是什么?
Sleep函数和wait函数的区别是什么?Notify和notifyall的区别是什么?
condition中线程是如何被唤醒的?什么是等待队列?
等待通知的经典面试题:使用三个线程1,2,3轮流打印10个数,线程1打印1,线程2打印2,线程3打印3,线程1打印4……
ThreadLocal有了解么?ThreadlocalMap的key 和value是什么?怎么保证内存不会泄露?
Java的线程池是怎么实现的?其原理是什么?线程池怎么设计核心线程数,拒绝策略怎么选择?怎么优雅关闭一个线程池?
Atomic包中的内容有了解过,atomicinteger 和atomicintegerFiledUpdater 的区别是什么?
Java安全的阻塞队列有哪些?分别提供了什么功能?
ParallelStream有使用过?底层的实现原理是什么?使用时应该注意哪些内容?
ConcurrentHashMap的源码有看过,说说其put和get流程?
聊聊ConcurrentHashMap扩容的过程?什么是协助扩容?
ConcurrentHashMap是怎么保证线程安全的?
JVM
Jvm内存模型?1.7版本,堆、栈(JVM栈+本地方法栈)、方法区、程序计数器。1.8版本,方法区改为元数据区,使用本地内存。字符串常量池:1.6在方法区,1.7在堆,1.8在元空间。
JVM堆栈异常分析
Jvm垃圾判断方法
Java四种引用
JVM垃圾回收算法
根节点枚举
安全点和安全区域
记忆集与卡表
写屏障
并发的可达性分析
Serial收集器/Serial old 收集器
ParNew收集器/Parallel Scavenge收集器/Parallel old收集器
CMS收集器
G1回收器
class文件结构
常见的java字节码指令集:加载与存储,运算符,类型转换,对象创建和访问,操作数栈管理,控制转移,方法调用和返回,异常处理,同步
java类加载机制?什么时候加载?加载、验证、准备、解析、初始化,使用、卸载
双亲委派模型
破坏双亲加载机制
常见的编译优化措施:方法内联、逃逸分析、公共子表达式消除、数组边界检查消除
字节码执行引擎
栈帧:局部变量表、操作数栈、返回地址等。
方法调用:解析和派发。派发的实现是通过虚函数表,该表会存放各个子类该方法的实际入口,如果不存在重写,就使用父类的地址。
基于栈的解释执行引擎:可移植,效率低。
动态语言支持:类型检查是在运行期,而不是编译期。函数指针。前3条方法调用指令,都存了this。而invokeDynamic存的是常量用于找到具体调用对象。
动态类型语言:只有值类型概念。
我的IT技术路摘录2
字节java后台面试
字节跳动面试有三轮技术面,前面两轮都有算法题,这是他们的特色,算法题一般还是比较复杂的,至少在我看来,阿里,腾讯,字节的在线coding中,字节是最难的,如果想要进字节的话,leetcode一定要多刷几遍,不然还是很难进的。下面给出我三轮面试的题目,希望给大家一点查考吧,至于面试答案的话,网上应该都有,这里就不给出了。
一面:
\1. 简单介绍一下你的技术站?
\2. Mysql的事务,幻读是怎么解决的?
\3. Mysql中锁的种类,行锁有哪些,分别怎么实现的?
\4. 分布式事务的实现原理?
\5. 分布式锁的实现几种方式?优缺点?
\6. Redis如果发生主备切换会有什么影响?
\7. 了解Redis的主从复制的原理么?
\8. Kafka和其他MQ的对比?
\9. 分布式uuid有了解么?雪花算法的原理?
\10. Netty的内存零拷贝技术的实现原理?
\11. Netty有哪些组件,其分别的功能是?
\12. Netty的线程模型描述一下?
算法题:leetcode 题目 打家劫舍2
二面:
\1. jvm 和jmm有了解哪些,详细介绍下?
\2. 创建对象的方法?
\3. 线程池的作用和原理?
\4. 设计一个线程池?
\5. Mysql的聚集索引和非聚集索引的区别?
\6. B+树的高度
\7. B+树的结构
\8. Https的整个过程?
\9. a和b的联合索引,select *from table where A>1 and b=2是否可以使用到索引
\10. Hash索引和b+树索引的区别?它们在使用方面的区别
算法题:完全二叉树最底层的最右边的节点
三面:
\1. 项目介绍
\2. 如果不想使用消息队列怎么增加mysql的性能提升?
\3. 项目中的分库分表的实现原理?
\4. 有什么想问我的吗?
阿里java后台面试
阿里的面试还是比较难的,尤其是后面的专家面,基本是一个问题接着一个问题的。相比较于腾讯和字节的面试来说,阿里的面试在于coding比较简单,一般是三道题,一个小时,一道算法题,一道设计模式题,一道多线程事件等待通知,其他的都还好。下面给出阿里的面试题目:
阿里一面:(电话 面试)
\1. 项目介绍
\2. 项目中分库分表的实现,怎么实现聚合查询
\3. 项目中怎么保证只提交一次,http请求的幂等性
\4. Jdk的双亲委派模型,如何破坏双亲委派模型
\5. 分布式锁的使用场景和原理,项目中是否有使用
\6. Java多线程了解么
\7. Mysql的索引介绍一下,在什么条件下索引失效,解释下最左前缀原则
\8. 进程的内存占用过高,要怎么排查
\9. Spring aop的实现原理
\10. 有什么想问的
阿里二面(在线笔试题):
1个小时三道题,不允许使用idea,只能手写,所以有些函数会写错,在旁边注释下
\1. leetcode原题第三题
\2. 设计模式策略模式的实现
\3. 多线程的等待通知的使用
阿里三面:
面试官有事直接到下一面了,幸运
阿里四面:(电话面试)
1.项目介绍,问的很详细,细节问题,优化点,如何优化的,性能对比,怎么实现的
2.rpc框架熟悉么,有了解哪些rpc的架构,分别说说优缺点,因为项目用了grpc,重点介绍了下这个框架
\3. grpc的序列化protobuf知道是怎么实现序列化后很小的,有了解过底层的原理吗?
4.你们项目用的是Redis哪个版本 ,知道其新特性么?为什么选用这个版本?
\5. Redis有几种部署方式,哨兵机制和集群的区别是啥?
6.有什么想问的么?
7.薪资和来杭州的意愿
阿里五面:(视频面试)
\1. 项目介绍
\2. 项目中是如何设计数据库的,其分库分表实现细节?要和具体到代码是怎么实现的?
\3. 你刚刚提到的一致性hash算法能描述下么?
\4. 在项目的过程中,你们项目是一个怎么样的演进过程?每年分别做了什么事情?
\5. Netty的线程模型描述一下,口述一下一个netty的服务端启动流程?(需要知道代码是怎么实现的)
\6. 怎么实现一个加锁的生产者消费者模型?口述一下condition的使用,消费者和生产者的代码
\7. 线程是怎么被唤醒的?
将AQS和condition中的等待队列和同步队列描述清楚
\8. Rpc了解么?说下rpc的流程
\9. Zookeeper在rpc框架中的作用?
\10. Zookeeper的写入过程是怎么实现的?
\11. 有什么需要问我的么?
腾讯java后台面试
相对阿里,字节的后台面试来说,腾讯的面试交流的很流畅,而且面试氛围也比价好,一般都是循序渐进的,如果不清楚,面试官也会指导你,从其他方面进行说明。因为算法一直都不是很好,尤其是动态规划这类的,在短时间内还是比较,所以四轮技术面,有三轮是有手写代码过程的。下面给出面试题目:
一面:(牛客网在线编程)
\1. 分布式事务的实现?
\2. Kafka如何实现消息幂等?怎么保证消息的可靠性?
\3. Kafka架构介绍一下?
\4. ConcurrenthashMap是怎么实现原理?
\5. 有什么想问的么?
算法题:字符串整数相加,如果有小数呢?
二面:(视频面试)
\1. 项目介绍
\2. 如果服务现在响应很慢,怎么查看?
\3. 如果是用户态cpu过高怎么解决,如果是内核态呢?
\4. http为什么会出现大量的time-wait?2msl的作用是什么?
\5. https和http知道么?为什么https要用证书?如果直接发公钥会怎么样?如果没有经过CA认证的证书访问会有什么风险?
\6. 假设现在有1万个优惠券,每个优惠券只能由一个抢到,每个人只能抢到一张优惠券,如何设计?
\7. 有什么想要问我的?
三面:(牛客网在线编程)
\1. 项目介绍
\2. 一致性hash算法
\3. 算法题:leetcode(96题不同的二叉搜索树)
\4. 有什么想要问我的?
四面:(面呗在线编程)
\1. 算法题:象棋8车问题
\2. Java的类加载机制
\3. Tomcat是怎么破坏的双亲委派模型的
\4. Springboot的如何去掉不用的配置,springboot不是开箱即用么?怎么把不要的配置去掉呢?
\5. Redis的主从复制原理?
\6. 有什么想要问我的?
一般java的面试要涉及到以下几个内容:java基础知识,多线程,JVM,网络,数据结构,算法,分布式系统,设计题,数据库,常用的中间件,zk,缓存redis,消息中间件等。现在我们就基于这些内容分模块的看下常见的问题总结。
java 面试–常见面试题(上)
##### 一.Java基础
一般java基础考察的是jdk源码(集合,IO,字符串,关键字),java的一些设计理念。如果对jdk源码感兴趣可以看下公众号中的jdk源码系列的文章。
\1. Java创建一个类的方法有几种?
\2. Java中== 和equals的区别是什么?
\3. 序列化的作用是什么?常见的序列化方法是什么?Java自带的序列化是怎么实现的?
\4. 解释下重载和重写的区别?
\5. 有了解过java的异常机制么?请结合项目描述一下你是怎么处理异常的?是否会自定义异常?
\6. Object类有去了解么?该类有哪些常用的方法,分别是怎么实现的?
\7. java的hashcode和equals方法的作用?什么时候会用到?
\8. String是一个基本类型么?那java的基本类型有哪些?String和stringBuffer和stringBuilder的区别是什么?
\9. String str="i"与 String str=new String("i")一样吗?不同点主要在哪里呢?
\10. 抽象类和接口的区别?抽象类一定要有抽象函数么?接口定义的变量一定是常量么?接口中可以定义函数的实现么?
\11. final、static关键字有了解,在java中的作用。抽象类可以使用final修饰么?
\12. final,finally,finalize分别是什么?
\13. Java的IO流有了解过,实现一个按行读取数据的方式。
\14. Java的反射原理是什么?Getclass和classforName的区别是什么?
\15. 如何实现一个list类型的深拷贝?Java的clone接口的作用是什么?
\16. Java的泛型的作用是什么?
\17. Java的注解有了解,其底层的实现原理是什么?怎么定义一个注解?
\18. Java中两个类的关系有多少种?有了解过设计模式么?
\19. Java的collection有几种?Collection和collections的区别是什么?
\20. ArrayLsit、LinkedList和vector的区别?它们是线程安全的么?如果想要线程安全应该要怎么实现?
\21. HashMap扩容机制?hashMap是线程安全的么?它和hashtable的区别是什么?hashMap key和value可以是null么?Hashmap的扩容一定是2^n么?1.8版本的优化点在哪里?什么时候链表转换为红黑树?什么时候红黑树转换为链表?Hashmap的get和put方法是怎么实现的?
\22. Queue中poll和remove方法的区别是什么?
\23. Iterator是什么?和splitIterator的区别是什么?
\24. ArrayList中怎么一边遍历一边删除?
\25. Treemap 和linkedHashMap有什么作用?其实现的原理是什么?
\26. HashSet的实现原理有了解?
\27. 静态内部类和内部类的区别是什么?为什么内部类可以访问外部类?
\28. 从安全性上说说java权限关键字private,protected,default,public的区别?
\29. 面向对象的概念是什么?Java的多态怎么实现?
\30. try {}里有一个return语句,那么紧跟在这个try后的finally {}里的code会不会被执行,什么时候被执行,在return前还是后?
##### 二.多线程
多线程是java的一名必修课,熟悉并掌握多线程在面试中很重要。一般多线程的面试集中在底层实现,基本概念,线程池等问题。如果对多线程的概念有兴趣可以看下公众号中多线程系列的文章。
\1. Volatile的作用是什么?底层是怎么实现的?缓存的一致性协议是什么?有没有了解过内存屏障?
\2. Synchronized 的原理有了解?和reentryLock的区别是什么?锁升级是指什么?
\3. 并发和并行的概念有了解?Java实现并发的方式有几种?
\4. 线程和进程的概念?守护线程是干什么的?常见的守护线程有哪些?
\5. Java怎么创建一个线程,native关键字的作用是什么?Thread类中绝大部分的方法是native的,有了解过怎么实现的么?
\6. Runnable和callable分别是什么?Future的作用是什么?
\7. 线程的状态有哪些?是怎么转换的?Jvm怎么查看线程的运行状态?
\8. Sleep和wait的区别?Notify和notifyall的区别是啥?
\9. AQS的源码有了解过?怎么实现一个公平锁和非公平锁?共享和非共享?
\10. Condition的源码有了解么?什么是等待队列,什么是同步队列?
\11. 多线程的三个基本特性是什么?Java是怎么实现原子性,有序性,一致性呢?
\12. Thread 类中的start和run方法的区别是什么?
\13. Threadlocal有了解过?其使用在哪些场景?ThreadlocalMap的key 和value是什么?怎么保证内存不会泄露
\14. Java的CAS是怎么实现的?Atomic包中的atmoicinteger 和atmoicintegerFiledUpdater 的区别是什么?分别在什么场景下使用?
\15. Java的线程池是怎么实现的?其原理是什么?线程池怎么设计核心线程数和最大线程数,拒绝策略怎么选择?怎么优雅关闭一个线程池?
\16. 了解死锁么?怎么防止死锁?
\17. ConcurrenthashMap的put方法?其扩容过程有了解过?
\18. Java安全的阻塞队列有哪些?分别提供了什么功能?
\19. Java中提供了哪些线程安全的队列?
\20. Fork-join框架有了解过?ParallelStream有使用过?
\21. 简述一下JMM,as-if-serial语义、happens-before模型?
##### 三.JVM
Jvm是高级java程序员必备知识,了解jvm有利于了解java运行的情况,并分析出现的各种复杂问题。Jvm的面试一般会问垃圾回收器,双亲委派模型,线网问题定位,类加载过程。
\1. JVM 的内存模型描述一下?
\2. 什么情况下会发生堆溢出?什么情况下会发生栈溢出?
\3. JVM内存为什么要分成新生代,老年代,持久代。新生代中为什么要分为Eden和Survivor?
\4. JVM 是怎么从新生代到老年代?一个完整的GC流程是怎样的?
\5. 简述一下垃圾回收器?说下各自的优缺点?有了解过cms和G1么?能详细说明一下么?
\6. 简述下垃圾回收算法?为什么新生代使用复制算法?
\7. 简述一下类加载过程,重点说明一下双亲委派模型,怎么破坏双亲委派模型?Tomat是怎么破坏的呢?
\8. 说说你了解的jvm参数和其作用?
\9. Java的四种引用有了解么?引用队列怎么使用?作用是什么?
\10. 怎么打出一个线程的堆栈信息?如果内存过高怎么分析?如果cpu过高怎么定位?
java 面试–常见面试题(中)
上一文中,我们总结了java面试的基础,多线程,jvm的常见面试题,本文我们继续介绍面试中网络、数据结构和算法、分布式理论和微服务的常见面试题。
##### 一.网络
网络的话,主要集中在tcp协议的考察,NIO的select,poll,epoll。https和http协议的考察。
\1. Tcp和udp的区别?Tcp的三次握手和四次分手?为什么要三次握手,为什么要四次分手?为什么会有time-wait,close-wait?出现大量的time-wait是什么原因?要怎么解决呢?
\2. IO的模型有哪几种?Reactor和preactor线程模型有了解?
\3. NIO的三大件分别是什么?Jdk 中Buffer和netty中buff的区别是什么?
\4. Channel和stream有什么不同?
\5. Select,poll,epoll的区别?Epoll的ET和LT分别是什么?有什么区别?在什么场景下使用?
\6. Tcp是怎么保证消息的可靠传输的?网络的拥塞控制和流量控制分别是指什么?Tcp的报文头有了解过,报文头怎么保证消息可靠性?
\7. 简述一下HTTP协议,http1.0,http1.1和http2.0的区别?
\8. 访问www.baidu.com发生了什么?DNS解析的流程有了解么?
\9. http请求哪些是幂等的?Get和post的区别是什么?常见的http状态码是什么?http的请求头有哪些参数,说说你知道的?
\10. 简述一下长连接和短链接,我们该怎么选择长连接和短连接?
\11. IOS七层协议有了解么?Ip协议是哪层协议?
\12. https的流程可以描述一下么?如果没有证书可以么?
\13. Cookie和session的区别是什么?
\14. 什么是分块传输?
##### 二.数据结构和算法
面试中数据结构常考的有数组、链表、队列、栈、堆、树、图、哈希表、跳跃表,常见的算法有排序算法、二分查找、动态规划、深度遍历、广度遍历、分治算法、回溯法等。
\1. 聊聊你知道的排序算法?其中算法时间复杂度、空间复杂度、稳定性和最坏最好的情况下的时间复杂度。
\2. 数组和链表的优缺点是什么?
\3. 如果现在要找出一个数组中top n的数,可以使用什么数据结构?
\4. 有了解过跳跃表么?其优点是什么?为什么Redis的zset使用跳跃表的结构?跳跃表的遍历时间复杂度是多少?
\5. 栈、队列的区别是什么?
\6. 前缀树的数据结构可以实现?在哪些地方可以使用?
\7. 红黑树有了解?什么时候发生左旋、右旋、换色?分别怎么实现?
\8. ALV树、二分查找树和红黑树的区别是什么?
\9. 完全二叉树和满二叉树的区别是什么?一颗高度为h的满二叉树的节点右多少个?如果换成是完全二叉树呢?
\10. 知道哪些hash算法,如果hash发生碰撞,常见的解决方案有哪些?
\11. B+树和B树的区别是什么?为什么innodb的索引使用B+树,其优点在哪里?B+树是怎么调节平衡的?一颗N个节点b介的B+树的高度是多少?
##### 三.分布式理论和微服务系统
分布式理论有两个基本的理论基础:CAP和BASE理论,一致性协议。涉及到的分布式知识有分布式UUID,分布式锁,分布式事务,分布式session等。
\1. 请简述一下CAP理论,我们常见的中间件分别侧重点是什么?简述一下BASE理论?
\2. 有了解过哪些一致性协议?Poxos、ZAB、raft协议有了解?有了解过gossip协议?什么是强一致性,弱一致性,最终一致性,顺序一致性。
\3. 分布式锁的实现方案?
\4. 分布式uuid的实现方案?
\5. 一致性hash算法了解么?
\6. 分布式事务的实现方案?
\7. 分布式session的实现方案?
\8. 接口如何实现幂等?
\9. 不同的系统怎么实现单点登入?怎么实现权限校验?
\10. 聊聊微服务治理,分别涉及到哪些方面?你们系统在高可靠上采取了哪些措施?应对高并发有什么方案?系统的监控运维和服务降级、熔断的方案是什么?
\11. SOA架构和微服务架构的区别?解释下微服务,分布式,一致性,幂等这些概念?它们之间有什么联系?
\12. 常见的负载均衡算法有哪些?
\13. 聊聊你理解的resful框架,和rpc框架的区别?
\14. 常见的rpc框架有哪些?Rpc框架的原理是什么?有没有自己实现过一个rpc框架?
\15. 如何做微服务的限流?常见的限流算法有哪些?漏桶算法和令牌桶算法的区别是什么?
聊聊微服务拆分?你们系统是怎么拆分的,这种拆分有什么优缺点?
java 面试–常见面试题(下)
在之前的两篇文章中,我们已经提到了java面试中的常见问题,还有部分内容,我们在本文也给出,希望对大家的面试过程有些帮助。这是我总结的最后一部分常见面试题:分别是数据库,基础框架,设计题。
##### 一.数据库
在数据库的面试中,常见的面试内容基本上是基于innodb存储引擎的内容,主要是索引的使用,事务,主从同步,分库分表的方案实现。
\1. 数据库的常用存储引擎有哪些?能重点介绍innodb和myisam的区别?
\2. B+树和hash索引的区别是什么?
\3. Innodb的行锁有哪几种?分别是怎么实现的?
\4. 数据库的乐观锁和悲观锁的区别?Select * from table for update,select *from table in share mode分别加的是什么锁?
\5. 索引在什么时候会失效?了解聚集索引和非聚集索引的区别么?覆盖索引是什么?
\6. Mysql的事务有那几个特性?ACID分别是怎么实现的?有几种隔离级别?分别是怎么实现的?默认的隔离级别是?
\7. Mysql是怎么实现主备同步的?同步的方式有几种?涉及到的三个线程分别怎么工作?
\8. 你们项目有使用分库分表?如何实现?如果要扩数据库节点的话,怎么实现?
\9. B+树的优点是什么?为什么mysql的索引使用b+树,为什么不使用B树或者红黑树呢?
\10. 数据库的三大范式是什么?最左前缀原则是什么?如果table有a,b有联合索引,那么Select *from table where a>0 and b=0 ; Select *from table where a=0 and b>0两个sql语句是否有使用索引?
\11. 什么是幻读?Mysql的innodb存储引擎是怎么解决幻读的?
\12. Mysql怎么优化,explain指令有了解过?索引怎么创建比较合适?
\13. 数据库会死锁么?Innodb是怎么解决死锁的?
\14. 如何安全的更改一行数据?
\15. In和exist的区别是什么?
\16. left join、right join,inner join的区别是什么?
##### 二.中间件和架构
一般常见的中间件,如果你在简历提到有哪些中间件,并且刚好面试官也熟悉这个中间件,那么基本就会问下这方面的内容。常见的面试热点有缓存(Redis,memcached,MongoDB),消息中间件(kafka,rocketMQ,rabbitMQ),zookeeper,rpc框架(grpc,dubbo,thrft),spring框架,dubbo框架,netty框架,mybaits,hibernate等。这里我了解的框架有Redis,kafka,zookeeper,rpc,spring,netty,mybaits等框架。所以下面的题目基本是这些框架的问题。
###### Netty面试题:
\1. simplechannelinboundhandler和channelinboundhandler的区别?
\2. netty的内存泄露的检测机制?
\3. Bytebuf中使用引用计数进行内存释放和占用?
\4. Attr和option的区别?
\5. Channelinitionlazier 的作用是什么?
\6. 如何从channel中引导一个新的客服端,这样做的好处是什么?
\7. Netty的内存零拷贝?
\8. Netty的高性能在哪些方面?和nio相比
\9. Channe与Socket是什么关系?Channel 与 EventLoop是什么关系,Channel 与ChannelPipeline是什么关系?
\10. Netty框架本身存在粘包半包问题?
\11. 何时接受客户端请求?
\12. 何时注册接受 Socket 并注册到对应的 EventLoop 管理的 Selector ?
\13. 客户端如何进行初始化?服务端如何创建?
\14. 何时创建的 DefaultChannelPipeline ?
\15. Netty内存池实现原理?
\16. netty中的对象池的分析?
\17. netty的心跳处理在弱网下怎么办。
\18. netty的hashwheeltimer的用法,实现原理,是否出现过调用不够准时,怎么解决。
###### Redis面试题:
\1. Redis的高性能体现在哪些方面?
\2. Redis的主备同步流程?
\3. Redis的事务怎么实现?有什么缺点?
\4. Redis有几种部署模式?重点讲下集群和哨兵机制的实现?
\5. Redis的常见数据类型?底层是怎么实现的?
\6. Redis的持久化过程?
\7. Redis的pipeline机制有了解过?集群下怎么实现?
\8. 常见的Redis的优化方案?
\9. 常见的Redis问题?缓存击穿,缓存雪崩,热点key问题解决方案?
\10. Redis在集群下做分布式锁有什么优缺点?
\11. Codis和Redis集群的区别?
\12. Redis的过期策略怎么实现的?Redis的淘汰策略是怎么实现的?
\13. Hyperloglog有使用过?怎么实现的?
\14. 如果Redis主备切换回发生什么问题?
\15. Redis的map类型是怎么实现扩容的?和jdk的hashmap的扩容有什么区别?
\16. Redis如果cpu过高,怎么解决?在使用中有出现什么问题?是怎么解决的?
\17. Redis的reactor模型能否介绍下?
\18. Redis结合lua有什么作用?Eval和evalsha的区别?
\19. 介绍下Redis的SDS的优势?RESP有了解么?
\20. 如果有海量的数据,怎么查询某个key是否存在?
\21. 如果要统计某一天的页面访问量怎么实现?
###### Kafka面试题:
\1. 集群的副本同步机制?
\2. Kafka消息的格式?
\3. Kafka的高性能的原因?
\4. 如果leader crash时,ISR为空怎么办?
\5. Kafka的生产者发送消息流程是怎么样?
\6. 如何保证消息只消费一次?如何保证消息不丢失?
\7. 如何增加写的性能?
\8. Kafka怎么判断一个broker是否还存活?
\9. Kafka怎么实现分区策略,怎么实现负载均衡?
\10. Kafka的reblance的流程?在什么情况下会发生reblance?
\11. Kafka消息的幂等性和事务是怎么实现的?
\12. Kafka的时间轮算法是怎么实现的?如果出现不准确怎么办?
\13. 如果kafka消费者消费超时会发生什么?怎么避免kafka的消费超时?
\14. Zookeeper在kafka中有哪些作用?
\15. Kakfa的ack机制?0,-1,1分别代表什么?
\16. Kafka是怎么实现选举的?哪些地方需要选举?
\17. 如何设计保证kakfa中有某个特征的消息的是严格按照顺序消费的?
\18. 有了解哪些消息队列?能否做下对比?
###### Zookeeper面试题:
\1. zookeeper的watch机制?
\2. Zookeeper如何扩容,扩容过程会不会有影响?
\3. Zk的数据是怎么同步的?
\4. 如何优化zk的性能?
\5. Zk的事务是怎么实现的?
\6. 使用zk实现分布式锁有哪些弊端?
\7. Zookeeper可以监听哪些数据?
\8. Zookeeper的节点有哪几种类型?
\9. Zookeeper为什么建议是奇数台部署?
\10. 如何使用zookeeper实现一个服务发现?
###### RPC框架的面试题:
\1. 常见的RPC框架有哪些?能否做个对比?
\2. Grpc框架的原理有了解?
\3. Rpc框架的原理介绍下?Zookeeper在框架中的作用是什么?
###### Spring面试题:
\1. 聊聊spring的IOC和AOP?其底层原理分别是什么?
\2. Spring支持哪几种注入的方式?
\3. BeanFactory和ApplicationContext有什么区别?BeanFactory和FactoryBean的区别?
\4. Bean的声明周期?Bean的作用域有几种?单例bean是线程安全的么?
\5. Springboot的启动流程?
\6. Spring有几种自动装配的方式?
\7. Spring有用到哪几种设计模式?Spring中主要的模块有哪些?
\8. Spring的事务有了解?管理方式有几种?声明式事务的实现原理是?传播级别有几种?
\9. Spring的事件类型有几种?
\10. Springmvc的流程?
\11. SpringMvc的控制器是不是单例模式,如果是,有什么问题,怎么解决?
\12. Spring的常用注解有哪些?分别代表什么意思?
\13. Spring怎么解决循环依赖问题的?
\14. SpringMvc里面拦截器是怎么写的?
\15. Spring AOP和AspectJ AOP有什么区别?
\16. Springcloud和dubbo的区别?
\17. ribbon和feign的区别?
\18. ribbon、feign以及hystrix的超时、重试设置?
\19. hystrix的隔离策略和zuul的功能是?
\20. 说说Eureka的服务发现过程?和zookeeper相比优势是什么?
###### Mybaits面试题:
\1. mapper的加载方式?
\2. selectOne和selectUser方法有什么区别?
\3. mybaits 的实现原理?
\4. Configuration参数中有哪些常用的?分别介绍一下?
\5. statementHandler 和prepareStatementHandler 的区别?
\6. mybaits的一级缓存和二级缓存的区别?
\7. #{}和${}的区别是什么?
\8. Mybatis是如何进行分页的?分页插件的原理是什么?
\9. 使用MyBatis的mapper接口调用时有哪些要求?
\10. Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
\11. 怎么使用mybaits实现分表功能?
##### 三.设计题
设计题是面试中一个必备环节,在现实中,面试官一般的设计题往往会给一个实际场景,问你怎么实现,会有什么问题,设计题无非高并发场景,持久化场景,数据库场景。这些设计题有一些基本的套路,我们需要实际中遇到问题去分析,然后使用相关的方案进行解决。
\1. 如何设计一个高并发的支付系统?
\2. 如何设计一个抢红包系统?
\3. 如何解决超卖现象?
\4. 如何设计一个线程池?
\5. 如何设计一个分布式coutdownlatch?
\6. 如何设计一个微博关注度的数据库?
\7. 如何设计一个抢购系统,如果用户在规定时间内没有付款则订单取消?
自学笔记问题摘录
多线程 - 极客
并发编程可以总结为三个核心问题?同步、分工、互斥
线程安全问题的三个源头?都如何解决?可见性、有序性、原子性。Java内存模型,互斥锁。
如何解决锁带来的性能问题?锁优化,各种粒度的锁。无锁,ThreadLocal、final,以及Copy-on-write。
如何解决锁带来的死锁问题?破坏死锁条件。
如何保证可见性、有序性? 按需禁用缓存及编译优化,volatile、synchronized、final,六/八项Happens-Before规则约束编译器优化行为
如何解决原子性问题?互斥锁。对共享资源的访问具有排他性。
原子性的本质是什么?本质其实不是不可分割,是多个资源间有一致性的要求,即中间状态对外不可见。
如何使用锁能提高性能?细粒度锁,用多把锁保护不同的资源。细粒度锁一定注意死锁问题。
Lock比Synchronized好在哪?1.可破坏占有且等待,即主动释放锁。2.Lock提供了管程模型的多个条件变量。
为什么需要等待-通知机制?避免等待互斥资源时,cpu循环消耗。
等待-通知机制原理及流程?
wait()和sleep()区别?
wait()实现的典型范式?为什么要这样做?
notify()和notifyAll()有什么区别?推荐用哪个?为什么?
如何保证线程安全性?避免出现原子性/可见性/有序性问题。非数据竞争(线程本地数据/不变模式),数据竞争->竞态条件->互斥->锁。
活跃性问题是啥?有哪些?如何解决?某个操作无法执行。死锁,活锁,饥饿...
如何提升性能?无锁、减少锁持有时间
如何计算串行对性能的影响?串行度为5%,性能最多提高所少?阿姆达尔(Amdahl)定律
性能指标有哪些?分别什么意思?吞吐量、并发量、延迟...
MESA管程模型是怎样的?分别如何解决互斥、同步问题?只允许一个线程进入管程。
三种管程模型有什么差别?如何唤醒。Hasen(哈森)执行完再notify()、Hoare(霍尔)阻塞自己等唤醒、MESA(弥撒)直接踢入入口等待队列。
synchronized的和管程什么关系?内置的精简MESA管程。只有一个条件变量。且自动加锁解锁。
synchronized和reentrantLock有什么区别和联系?都是MESA管程,前者一个变量、自动加解锁。
通用的线程生命周期有哪些?怎么转换?
Java线程生命周期有哪些?和通用的生命周期有什么区别?调用阻塞API时,如IO,JVM和OS层面的线程状态怎么转换?
Java线程生命周期怎么转换?
stop()和interrupt()有什么区别?
被 interrupt 的线程,怎么收到通知?休眠、运行且阻塞Api、运行
如何通过日志及工具诊断多线程运行时Bug?
为什么要使用多线程?从优化算法、硬件优化(CPU/IO)、硬件单一利用率、硬件综合利用率回答。
单核主机用多线程有意义吗?有意义,IO密集型。
为什么Redis单线程却很快?Redis把读写操作都放在了CPU和内存,几乎没有I/O。又减少了多线程上下文切换的过程,因此Redis即便是单线程也很快。
线程设置多少合理?计算密集、I/O密集,按比例,单核/多核。
局部变量是线程安全的吗?为什么?线程->调用栈->栈帧。
线程和调用栈的对应关系?一个调用栈对应几个线程?
线程封闭是啥?举个例子?
如何封装共享变量?
如何识别共享变量间的约束条件?
并发访问共享变量的策略,有哪些方法?
写好并发程序,有哪些经验或方法论?
synchronized和Lock有什么区别?
Lock的可见性是怎么保证的?顺序、`volatile`、传递性原则。
什么是可重入锁?什么是公平锁?
用锁的最佳实践? try{} finally{unlock();} 和 while(条件不满足) {await();}。Java 并发编程
synchronized或lock&condition的使用范式?以入队出队为例
Java锁和条件的实现原理?
怎么实现TCP异步转同步?
什么是PV操作/信号量?模型?
PV操作怎么用?
为什么有了Lock还要Semaphore?Semaphore 可以允许多个线程访问一个临界区。
信号量唤醒时,是随机唤醒等待队列还是按顺序?这样有没有问题?
实现一个限流器?
什么是读写锁?用来解决什么问题?和互斥锁什么区别?ReadWriteLock
用读写锁实现一个Cathe缓存工具类
读写锁是否支持锁的升级?锁的降级呢?为什么?
StampedLock和ReadWriteLock的区别?
StampedLock原理?
使用StampedLock要注意啥?(和ReadWriteLock的区别,interruput导致cpu飙升问题)
CountDownLatch用来做什么的?怎么用?代码举例?
CyclicBarrier用来做什么的?怎么用?代码举例?
CountDownLatch和CyclicBarrier的区别?
怎样把一个线程不安全的容器变成线程安全?
常用的同步容器有哪些?四大类,工具类...
同步容器和并发容器区别?
常用的并发容器有哪些?各实现原理?四大类...
哪些队列是支持有界的?
什么是Java的快速失败机制?如何避免?
JUC使用无锁方案的示例?
无锁方案的原理?
什么是CAS?CAS的原理?CAS能够保证原子性吗?CAS条件不满足时怎么处理?
什么是ABA问题?什么时候需要关心ABA问题?怎么处理?
Java如何实现CAS?调用了哪些方法底层怎么实现?使用CAS的范式?
常用的原子类有哪些?各怎么实现?
为什么要用线程池?
线程池底层原理?怎么实现的?
Java线程池的几个关键参数?构造函数的参数有哪些?
实际使用线程池要注意什么?
ThreadPoolExecutor的execute()和submit()什么区别?
线程池执行时如何获取任务执行结果?
Future的是什么?有哪些方法?怎么用?
ThreadPoolExecutor 有几个 submit()方法?有什么区别?怎么用?
FutureTask 工具类如何使用?
实现一个烧水泡茶程序?模拟两线程之间的配合?用Thread方式,再用线程池方式实现。
做一个询价应用,这个应用需要从三个电商询价,然后保存在自己的数据库里?
为什么要使用CompletableFuture?
CompletableFuture怎么新建对象?几种方法有哪些区别?使用时要注意什么?
CompletableFuture怎么获取操作执行结果?
CompletionStage 接口和CompletableFuture什么关系?是用来干啥的?
CompletionStage 接口有哪几大类方法?有什么区别?
CompletionStage 接口如何处理异常?
如何解决批量异步任务谁先返回谁先执行后续操作?
CompletionService接口的实现原理?实现类?实现类两个构造方法的区别?
CompletionService接口有哪些方法?
如何实现调用多个查询服务,只要有一个返回整个服务就可以返回?
ExecutorCompletionService有必要自己提供线程池吗?
Fork/Join框架用来解决什么问题?
分治算法怎么执行?任务模型?
使用Fork/Join计算斐波那契数列?
ForkJoinPool 工作原理?几个任务队列?窃取机制?双端队列?
用Fork/Join统计单词数量?
使用Fork/Join要注意什么?
对于一个 CPU 密集型计算程序,在单核 CPU 上,使用 Fork/Join 并行计算框架是否能够提高性能呢?
简单说说Actor模型?有什么优缺点?处理、存储、通信。适用于分布式。理论上不保证消息百分百送达,不保证送达顺序性,不保证一定处理
简单说说软件事务内存?有什么优缺点?借鉴数据库事务。但I/O很难支持回滚。所以目前支持 STM 的编程语言主要是函数式语言。
简单说说协程?有什么优缺点?从OS来看,线程在内核态中调度,协程在用户态调度,更轻。协程也有自己的栈几十K,线程至少1M。Loom。
简单说说CSP模型?有什么优缺点?不要以共享内存方式通信,要以通信方式共享内存。本质上是要避免共享。
CSP 模型与 Actor 模型的区别?1.管道是否可见。2.是否阻塞。3.是否保证消息全部送达。Java的库是JCSP,但是还不成熟。
JVM - 深入理解Java虚拟机
-- 1章
略
-- 2章
JVM内存有哪些区域?
各区域作用?存储什么数据?
各区域作用生命周期?在什么时候被创建?
各区域会抛出什么异常?在什么情况下抛出?
方法区有哪些东西?各存在哪里?
new一个对象发生了什么?
Hotspot的Java堆中的对象,包含了哪些信息?内存布局是怎么样的?对象头存储什么信息?实例数据存储顺序?为什么要有对齐填充?
如何定位、访问到堆中对象的具体位置?有哪些访问方式?各有什么区别优势劣势?Hotspot使用的哪种?
模拟堆、栈(本地方法栈/JVM栈)、方法区(方法区/运行时常量池)、本地内存OOM?JVM参数?怎么模拟?遇到这个问题怎么排查处理?
所有的对象都是在堆上的吗?类对象在方法区,字符串常量对象在堆上,常量池保存了首次遇到的该字符串的引用。
方法区内存怎么回收?包括卸载类、常量
直接内存什么情况下容易OOM?如何模拟?
-- 3章
如何判断对象是否能回收?有哪些算法?有啥优缺点?
GC Roots的对象包含哪些?
Java中有哪些引用类型?各有什么区别和用途?
对象被回收的过程?几次标记?finalize()方法有什么用?
方法区GC主要回收哪些内容?如何判定需要回收?是否有必要回收?
Java堆为什么要分代?基于什么理论?跨代引用怎么解决?
GC回收算法有哪些?具体实现?各有什么优缺点?
详细列举Hotspot标记的过程,包括根节点枚举、安全点、安全区域、记忆集、写屏障、可达性分析等?
为什么会有安全点?安全点安全在哪?怎么选取安全点位置?GC时如何等待程序到达安全点?如何保证轮询标志高效?
安全区域用来干什么的?如何实现?
记忆集用来干什么?如何实现?什么是卡表?
如何保证编译执行时能够维护卡表?伪共享问题怎么解决?
并发的可达性分析如何实行?如何防止用户线程和分析并发时,需要的对象被误删除?
常用的7种经典GC收集器?它们各自的原理特点?适用于哪些场景?哪些可以相互搭配使用?
Shenandoah与G1的异同?工作阶段?如何实现并发回收?Brooks Pointer是什么?
ZGC最具有特色的技术是啥?染色指针如何实现?工作阶段?
如何进行GC收集器选型?
-- 4章
常用本地工具作用?jps, jstat, jmap, jhat, jstack, jinfo?jps查看虚拟机线程ID,jstat查看堆和GC分配,jmap导出堆快照dump,jhat分析dump,jstack查看栈线程状态和锁,jinfo虚拟机配置等。
JDK 7及其以后版本的HotSpot虚拟机选择把静态变量与类型在Java语言一端的映射Class对象存放在一起,存储于Java堆之中。在JDK 7以前,即还没有开始“去永久代”行动时,这些静态变量是存放在永久代上的,JDK 7起把静态变量、字符常量这些从永久代移除出去。
常用的可视化分析工具?JHSDB
HSDIS:JIT生成代码反汇编有什么用?
-- 5章
略
-- 6章
为什么要有.class文件?java直接像js一样解释源代码执行也可以呀?自己的思考:1.提高性能,js生产中一般也是压缩的。将代码转为字节码。2.解耦java和jvm,实现jvm语言无关性。
.class文件有几类数据项?.class文件的结构?这张大表包含哪些数据项和表?
u1的u是代表字节还是字?
可编译的最大方法、字段名长度?为什么?理论上.class可支持的最大栈深度?最多字段量?方法代码最多多长?UTF8为u2,Code属性表栈深度和字段槽长度为u2,65536。code_length为u4,实际只用了u2。
常量池里面存什么东西?有哪些表?
属性表用来做什么?举个例子。Java泛型是伪泛型,是Object,那么反射是,信息从哪里获取?方法的代码就是编译成字节码存放到方法表的code属性表里。
Signature属性用来做什么?Code属性主要由哪些数据项和表?
byte、char、short,boolean在虚拟机中当什么类型处理?
字节码指令最多有几条?有哪些种类?各用来干什么?列举几条常用的?
异常用哪条指令抛出?两种情况
同步用哪条指令实现?两种情况。方法级:在方法表上用字段标注。同步块:monitorenter + monitorexit。
-- 7章
你觉得Java语言最大的特点?1.虚拟机自动垃圾回收。2.运行期加载。
运行期加载的优缺点?
类加载的顺序及生命周期?何时进行加载?何时进行解析(为何)?何时进行初始化?接口与类的初始化有何不同?
加载阶段完成什么工作?整体流程?哪里有扩展点?数组和非数组类加载有何区别?
为什么需要验证?验证阶段完成哪些工作?分哪几个验证阶段?
准备阶段用来干啥?public int a=1, public static int a=1,public static final int a=1赋值了几次?分别在哪完成?1..2两次,准备及初始化的构造方法中。3一次,常量属性里。
解析阶段何时发生?需要解析哪些内容?如何解析查找?
类初始化阶段的过程?
类加载器如何判断两个类相等?
类加载器有哪些分类?什么是双亲委派模型?解决了什么问题?碰到类先给爹加载
有哪些情况下没有用到双亲委派模型?
模块化的目的是什么?OSGi用来干啥的?JDK9用哪些规则保证了兼容性?双亲委派模型进行了哪些更改?
-- 8章
栈帧的结构组成?
局部变量表存了什么?变量槽怎么重用?
操作数栈用来做什么?有什么优化?
方法符号引用何时转化为直接引用?具体方法调用指令有哪些?什么是虚方法?哪些方法会被解析?哪些会被分派?
重载和重写有什么区别?前者是静态分派(有些资料也归为解析),后者是动态分派。
详细解释静态分派与动态分派?
字段参与多态吗?动态分派对字段有效吗?为什么?
Java是单分派还是多分派?静态动态都是单分派吗?
动态分派有哪些优化?虚方法表用来干什么?实现原理?
什么是动态类型语言?与动态语言、弱类型语言概念一样吗?
为什么要有invokedynamic指令?用老的指令实现有什么困难?
java.lang.invoke包用来做什么?方法句柄方式引用方法和反射方式引用方法有什么区别?Java里想把方法作为形参传入,怎么做?
invokedynamic指令用来做什么?参数是什么意思?包含了哪些信息?和普通的invoke*指令有什么区别?
孙子想引用爷爷的方法,怎么引用?其他代码不改变。方法句柄。
解释执行和编译执行的区别?结合编译原理流程说明及距离。
栈和寄存器指令集有何区别?
简要说说字节码在JVM的解释执行过程?有哪些部分需要参与?用四则运算举例?
-- 9章
列举一个正常使用自定义类加载器的例子?Tomcat为什么要进行类库分类?它的类库目录和自定义类加载器实现?Spring如何访问到不在它加载范围内的用户程序?
列举一个灵活使用自定义类加载器的例子?OSGi的静态、动态模块化简要介绍下?
动态代理如何实现?Java层面Api?字节码层面?
Backport工具原理?大概说一下
在服务器端执行临时代码,有哪些思路?
-- 10章
编译器主要有哪三种?各有什么区别?
Javac编译器用什么语言实现?
前端编译可以分为哪几个过程?各阶段主要做什么?1个准备,3个处理。结合那张图说一下即可。
解析的目的?填充符号表的目的?抽象语法树
插入式注解处理器可以用来干啥?程序员修改语法树
语义分析的目的?分为哪两个过程?举个例子?前面的过程保证语法树结构正确,本大爷则保证结合上下文分析来保证语义逻辑正确
\<init\>()方法和类构造器\<clinit\>()方法在哪个阶段添加到语法树的?它们都需要调用父类的构造器吗?
Java泛型和C#泛型的实现方式区别?有啥缺点和优点?只是在编译器实现。类型信息保存到变量表signature字段。
Java的泛型类型擦除如何实现?什么是裸类型?Java的泛型仅仅在编译器层面实现。
什么是值类型?未来泛型实现的方式思路?
泛型、自动装箱、自动拆箱、遍历循环、变长参数、条件编译的底层实现方式?使用包装类时,它们的"=="和"equals()"有何特点?
除了以上,还有哪些语法糖?
如何实现一个代码命名规范校验工具?讲讲思路。插入式注解处理器API。
-- 11章
什么是后端编译器?JVM规范有规定如何实现吗?
什么是即时编译器?完成什么功能?
为什么HotSpot要使用解释器与即时编译器并存的架构?它们是互补的。。。
(为什么HotSpot要实现两个(或三个)不同的即时编译器?)
(程序什么时候使用解释器执行?什么时候使用编译器执行?)
(哪些程序代码会被编译为本地代码?如何编译本地代码?)
(怎么从外部观察即时编译器的编译过程和编译结果?)
什么是解释器、C1、C2,它们有什么区别?如何配合工作?
什么是热点代码?如何进行热点探测?有哪些方法?优缺点?Hotspot用的哪个?
Hotspot方法调用计数器的执行逻辑?回边计数器的执行逻辑?
C1编译器如何编译代码?C2编译器如何编译代码?
提前编译有哪些思路?两个思路
比起提前编译,即时编译有哪些无法替代的优点?3个
列举几个常用的经典的编译器优化技术?各自说说他们的特点
方法内联是什么?JVM如何解决方法内联和虚方法的矛盾?
什么是逃逸分析?可以根据它的结果来做什么优化?各有什么特点?
常见的检查消除有哪些?检查消除有哪些思路?2个
-- 12章
为什么要用多线程?
什么是缓存一致性?什么是乱序执行优化?CPU能保证一致性和顺序性吗?只能按协议读写,按结果保证。
说说Java的内存模型?画图表述线程、主内存、工作内存怎么交互的?
大概描述性Java内存模型中主内存与工作内存之间具体的交互协议?包括8种操作,及其对操作先后性的要求,及其对操作需要同时满足的要求,及其对volatile的要求。
volatile关键字的含义?基于volatile变量的操作是线程安全的吗?具体怎么生效?底层的操作规定怎么保证volatile的语义?可见性、不可指令重排。不安全,运算符不是原子操作。底层是内存屏障,硬件层面把当前cpu最新缓存写入内存,从而让其他cpu的缓存失效,然后同时lock锁定禁止重排序。再底层是几个对操作的规则,比较复杂。
对long和double型变量的特殊规则怎么处理?分别在32/64位有风险吗?实际编程是是否都要加上volatile?
原子性、可见性、有序性分别如何实现?哪些关键字可以实现?底层是哪些操作以及哪些规则来支持?
先行发生是什么意思?先行发生原则用来做什么?
有哪些先行发生原则?“时间上的先发生”与“先行发生”有关系吗?
并发和多线程什么关系?
什么是用户态什么是内核态?进程和线程有什么区别?
线程的实现方式有哪些?各有什么优缺点?
线程调度有哪些方式?各有什么优缺点?线程优先级是稳定的吗?
Java的线程有几种状态?各个状态如何转换?
哪些动作会到时有限等待?哪些动作会导致无限等待?等待和阻塞有什么区别?
为什么要用到协程?
内核线程为什么切换成本高?
协程的优势和劣势?一个2G内存的服务器,大概最多可以开多少个线程?多少个协程?
内核式切换、抢占式切换有什么区别?内核线程、用户线程、协程、栈纠缠、有栈线程、无栈线程、纤程有什么区别?
纤程是什么?性能进步有多大?Java纤程新并发模型结构?Quasar的实现原理?
MySQL - 极客
在 MySQL 的 `information_schema` 库的 `innodb_trx` 表中,可查询当前执行中的事务。从而发现长事务。
用 `show variables` 来查看当前各种系统配置。如数据库隔离级别。
查询"XX"表varialexx参数,可看到各种配置。
*`show processlist` 命令*:分析原因,我们一般直接执行 `show processlist` 命令,看看当前执行语句处于什么状态。
*kill query + 线程 id*:终止这个线程中正在执行的语句;
*kill connection + 线程 id*:断开这个线程的连接(如果该线程有语句在执行,则先停止语句执行)。connection可以省略。
*怎么查出是谁占着写锁呢*?MySQL 5.7 版本及以上,可以通过 `sys.innodb_lock_waits` 表查到。
*Buffer Pool多大合适*:InnoDB Buffer Pool 的大小是由参数 innodb_buffer_pool_size 确定的,一般建议设置成可用物理内存的 60%~80%。
Buffer Pool:LRU,分两段防止全表扫描
redo_log:支持事务
binlog:支持存档、其他数据库
redo_buffer
change_buffer
sort_buffer
net_buffer
join_buffer
netbuffer
配置:双“1”,全局事务ID GTID,binlog row模式便于快速回复,测试时可以开慢日志查看扫描行数。
-- 1.基础架构
#一条SQL查询语句在MySQL里怎么执行?结合MySQL架构谈一谈,连接器、查询缓存(8.0取消)、分析器、优化器、执行器,各是什么功能?
连接器长连接太多会导致什么问题?需要注意什么?
判断SQL语句中的表或字段存不存在,在哪个阶段?在分析器阶段就执行了,MySQL受Oracle影响很大。
那么为什么表权限不能在分析器阶段就判断,而是延迟到执行器呢?因为SQL语句要操作的表不仅仅是字面上那些表,比如说触发器涉及的表,就不在SQL语句里。
-- 2.日志系统:如果 redo log 和 binlog 是完整的,MySQL 如何保证 crash-safe
redo log用来做什么?也是记录到磁盘上的。减少了查找和IO的成本。写入计算操作完成。
更新某一条记录时redo log操作的内部执行流程?直接写入redo log并更新内存就算更新完成。redo log文件固定大小,循环写入。具体是由两个指针控制......
#binlog 和 redo log的区别?两阶段提交?
##一条update语句在MySQL的执行过程?连接器->(查询缓存)->分析器->优化器->执行器(binlog)->引擎(changeBuffer,buffer pool, 刷脏页,redolog(redoLogBuffer, pagecache, fsync)),其他:sort_buffer
如何将数据库恢复到半个月前任一秒的状态?
参数配置:redolog和binlog参数配置建议?双1,每次事务都罗落盘。
日志一天一备好还是一周一备好?综合考虑,备份需要性能资源。另外,一天一备的话,恢复起来速度会更快。
-- 3.事务隔离级别
事务4个特性ACID?
什么是事务的隔离级别?用来解决什么问题?举例说明不同隔离级别下事务表现?
隔离级别是如何实现的?
*为什么mysql选可重复读作为默认的隔离级别*?Oracle等都是读已提交。我们在项目中MySQL一般也是用读已提交(Read Commited)。其他:见博客。
参数配置:MySQL 的隔离级别如何配置?
事务隔离的具体实现?回滚日志?
为什么要少用长事务?会产生大量redolog,会长时间占用锁。
事务有哪些启动方式?
参数配置?如何配置事务启动方式?
*用什么方案来避免出现或者处理长事务*?这个问题,我们可以从应用开发端和数据库端来看。information_schema.Innodb_trx 表
-- 4.索引(上)
说说常见的三种索引模型?哈希、有序数组、二叉树。
#*InnoDB使用什么结构?和MyISAM有啥区别?和B树有啥区别*?
#主键索引和非主键索引有啥区别?聚集索引和非聚集索引区别?
插入一个记录时,B+树有可能触发哪些变化?
使用自增的ID有什么意义?正好都是向后追加,不涉及挪动其他记录,也不会出发叶子节点分裂。
用短主键的意义?
为什么要重建索引?*重建索引,语句怎么写*?
-- 5.索引(下)
**MySQL索引可以如何优化**?高频、低频、
什么是覆盖索引?
什么是最左前缀原则?
什么是索引下推优化?
-- 6.全局锁和表锁:Server层实现
全库逻辑备份有哪些方法?各有啥特点?如何选择?引擎有事务用mysqldump --single-transaction、没有用全局锁FTWRL、不推荐`set global readonly=true`
如何用MyISAM实现事务?表锁。lock tables … read/write。注意表锁是能执行且只能执行某几张表的XX操作。
线上修改表结构要注意什么坑?1.全数据扫描。2.会同时拿读写锁,阻塞读操作。
#如何安全的给热点小表加字段?有长事务先干掉。一次一次试,等待时间太长就放弃再重试。
当备库用–single-transaction 做逻辑备份的时候,如果从主库的 binlog 传来一个 DDL 语句会怎么样?(后续看完主从复制可以回过头来看这里)
-- 7.行锁:引擎层实现
#InnoDB中,行锁什么时候获取到?什么时候释放?两阶段锁协议,用到时才回去获取。
如何安排正确的事务语句顺序?如果事务中需要锁多行,那么最可能冲突的锁放前面还是后面?为什么?
举个MySQL死锁的例子?如何解决死锁?
如何解决热点数据的死锁检测CPU消耗过高问题?
如果你要删除一个表里面的前 10000 行数据,有以下三种方法可以做到:
- 第一种,直接执行 delete from T limit 10000;
- 第二种,在一个连接中循环执行 20 次 delete from T limit 500;
- 第三种,在 20 个连接中同时执行 delete from T limit 500。
你会选择哪一种方法呢?为什么呢?
-- 8.事务MVCC
*可重复读和序列化隔离级别,底层怎么实现*?
#*MVCC和RR/RC事务隔离是怎么运作的*?快照,事务ID,数据版本,事务可视数组,高低水位。查询时:一致性读。更新时:当前读/阻塞。
更新的时候,更新的是哪个版本的数据?当前读。看不到也会更新。
-- 9.唯一索引,change buffer
字段长的属性适合做主键吗?不适合。二级索引存的都是主键。
唯一的字段,选择普通索引或唯一索引,对查询效率有什么影响?
#唯一的字段,选择普通索引或唯一索引,对更新效率有什么影响?buffer pool,changebuffer,merge
changeBuffer最适合什么业务场景?写多读少、机械磁盘。
change buffer 一开始是写内存的,那么如果这个时候机器掉电重启,会不会导致 change buffer 丢失呢?
**changebuffer和redo log有什么区别**?一条语句插入的过程?前者节省随机读IO,后者节省随机写IO。
#change buffer 一开始是写内存的,那么如果这个时候机器掉电重启,会不会导致 change buffer 丢失呢?不会丢。虽然是只更新内存,但是在事务提交的时候,我们把 change buffer 的操作也记录到 redo log 里了,所以崩溃恢复的时候,change buffer 也能找回来。
-- 10.优化器如何决定走哪个索引
#使用索引时,分析器评判索引时,什么索引是好索引?扫描行数、是否回表、排序、临时表。
explain可以着重看哪些参数?
如何取得索引基数?索引基数统计信息存在哪?采样。数据页。
*优化器如何判断走不走索引?如何判断走哪条索引?*索引基数+是否回表+是否临时表+是否排序等。
什么情况下会导致索引统计扫描条数错误?
-- 11.字符串索引
*字符串索引怎么建立*?
如何确定前缀索引长度?
-- 12.刷脏页
#InnoB的更新操作是写到redo log,redo log什么时候flush?四种情况下会flush
flush时对MySQL性能会有什么影响?4种情况,分情况讨论
InnoDB 刷脏页可以怎么优化?xxx参数(补全)
InnoDB刷脏页的速度怎么确定?cap * R%
#解决MySQL“抖动”问题?机器IO不高,但是MySQL就是卡?需要调节哪些参数?两个都是同样的问题。设置IO能力,脏页比例参数。以及可以加大内存。关键就两个点:内存脏页比例,redo log是否写满。
-- 13.删除数据导致空洞占用空间
InnoDB的数据删除流程?删除N行会怎样?为什么删除数据,文件大小不变?删除行、数据页、表。
#drop table效率为什么比delete效率高?前者直接删除,后者一个一个标记,留位置后续复用。
表重建有什么用?MySQL重建表的命令?流程?
Inplace啥意思?Online呢?
optimize table、analyze table 和 alter table 的区别?
-- 14.count(*)语句
InnoDB和MyISAM如何实现count(\*) ?
如有有一个计数经常被用到,如何提高查询效率?自己单独建一张表存计数。就不用每次都去扫描数据行数
#count(\*)、count(主键 id)、count(字段) 和 count(1)有什么区别?
用单独一张表计数的场景,从并发系统性能的角度考虑,你觉得在这个事务序列里,应该先插入操作记录,还是应该先更新计数表呢?先更新计数表,*插入会取写锁,要减少写锁等待时间*。?
当 MySQL 去更新一行,但是要修改的值跟原来的值是相同的,这时候 MySQL 会真的去执行一次修改吗?还是看到值相同就直接返回呢?加锁直接验证,很容易得出答案。该修改的修改,该更新的更新。
-- 15.前文知识简要串联
#两阶段提交时MySQL重启,数据如何恢复?
redo log 和 binlog 是怎么关联起来的? XID
#为什么还要两阶段提交呢?干脆先 redo log 写完,再写 binlog。崩溃恢复的时候,必须得两个日志都完整不就完了?binlog 写入的时候失败,**InnoDB 又回滚不了**
-- 16.order by,有哪些排序算法
#order by底层怎么实现?有什么区别?走不走索引?有哪些索引?底层是排序。有:全字段排序、rowid排序、索引排序、联合索引排序。
如何优化 select city,name,age from t where city='杭州' order by name limit 1000 ?有哪些思路
-- 17.使用临时表排序
内存临时表排序执行流程?使用什么引擎?
磁盘临时表排序执行流程?使用什么引擎?
随机取一个值,访问频率很高,怎么设计?
上面的随机算法 3 的总扫描行数是 C+(Y1+1)+(Y2+1)+(Y3+1),实际上它还是可以继续优化,来进一步减少扫描行数的。如果你是这个需求的开发人员,你会怎么做,来减少扫描行数呢?说说你的方案,并说明你的方案需要的扫描行数。
-- 18.破坏索引条件:函数操作、隐式类型转换、隐式字符编码转换
设计索引使用的字段时,举例说说有哪些索引失效的场景?见上面教训。
-- 19.表锁、行锁、一致性读
查询一条语句,执行得很慢,有可能是哪些原因?怎么操作分析解决?分析是表级锁、行锁、还是一致性读的问题。用*慢查询日志识别慢查询,用show processlist*,看下有没有阻塞的state。然后查sys.sys.schema_table_lock_waits表的blocking_pid,直接把它kill掉。
怎样加读锁?怎样加写锁?都是什么含义?for update,in share lock。含义参照前文基础篇。
-- 20.幻读原理。间隙锁、死锁
幻读是什么?
幻读引起了什么问题?举例?语义问题,明明说锁,还是锁不住。数据一致性问题。
#如何解决幻读问题?这种解决方式有什么问题?可重复读的情景下,会有幻读,间隙锁在该场景下才生效。
你们公司MySQL用什么隔离级别?要注意什么?用间隙锁:可重复读。不用间隙锁:读已提交+binlog_format=row
读已提交和可重复读有什么区别?
-- 还要再看下。21.间隙锁和行锁的加锁规则
可重复读隔离级别下,InnoDB加锁的规则?
-- 22.临时提升mySQL性能
线上如何短时间提升短连接数性能?
#如何解决线上慢查询问题?
#突发QPS怎么解决?
你是否碰到过,在业务高峰期需要临时救火的场景?你又是怎么处理的呢?
-- 23.MySQL 是“怎么保证 redo log 和 binlog 是完整的”:生产用双1配置。
#binlog的整体写入机制?data -> binlog cache -> page cache -> 磁盘
#redo log的整体写入机制?data -> redo log buffer -> page cache -> 磁盘。可能会在任一状态,后台自动刷。双1配置时,prepare阶段会持久化一次。
*binlog和redo log的完整写入机制?包括中途cash怎么办?*参照第15篇和本篇文章
如果 redo log 和 binlog 是完整的,MySQL 是如何保证 crash-safe 的?
MySQL 是“怎么保证 redo log 和 binlog 是完整的?
什么是组提交机制?每次多等几个事务到prepare,再fsync
为什么说WAL 机制可以减少磁盘写?顺序写,组提交机制
*生产是设置为双1吗*?为什么?风险?有调到非双1的时候,在大促时非核心库和从库延迟较多的情况。
-- 24.主备一致(最终一致性)
主从模式,需要把从库设为只读吗?为什么?只读会不会阻塞主从同步?
更新一条语句,主备底层流程?
#binlog有几种格式?各有什么区别?优缺点?语句在主备可能执行不一致,但是省空间。另一个反之。mixed兼备。
生产环境binlog用什么格式?row格式,误操作时如何恢复数据?用什么工具?能手动copy执行吗?
双M结构,日志循环复制问题怎么解决?
#说到循环复制问题的时候,我们说 MySQL 通过判断 server id 的方式,断掉死循环。但是,这个机制其实并不完备,在某些场景下,还是有可能出现死循环。你能构造出一个这样的场景吗?又应该怎么解决呢?
-- 25.主备延迟 + 主动主备切换。要保证高可用,最终一致性还不够。
什么是主备延迟?是怎么计算出来的?主备库时间不一致,算出来的延迟准吗?
主备延迟主要的延迟来源?是什么导致的?各怎么处理?备库消费比主库生产慢。硬件...
主备切换有哪些切换策略?各有什么特点?如何抉择?
发生异常导致主备切换会是什么效果?比如主库直接掉电?一定是SBM=0才会切换
-- 26.备库为什么延迟:备库用并行复制能力减少延迟
#*备库追不上主库甚至差几个小时是什么原因*?怎么解决?升级DB版本。调参,调大worker数。
各个版本的备库worker分发策略?按表分配?按行分配?按commit组并行?按prepare事务并行?按WRITESET并行?
-- 27.一主多从:怎样保证切换正确性
#什么是一主多从架构?主库故障时如何切换?除了一主多从还有哪些集群模式?关键就是同步点位,以及GTID。
主从切换时可能会有什么坑?怎么处理?不能精确定位同步位点。手动一一跳过事务,或忽略错误。
GTID是什么?GTID模式怎么切换?其实就是提交一个事务,集合里增加一个GTID。主从切换时,根据GTID的差集,来确定开始复制binlog的位置即可。
你在 GTID 模式下设置主从关系的时候,从库执行 start slave 命令后,*主库发现需要的 binlog 已经被删除掉了,导致主备创建不成功*。这种情况下,你觉得可以怎么处理呢?
-- 28.一主多从:怎样保证查询正确性.怎么处理主备延迟导致的读写分离问题
#主从模式,主库刚更新完一个数据,从库读不到最新的数据怎么办?有哪些处理方法?select master_pos_wait(file, pos[, timeout]);命令。或5.7.6后事务执行后会返回gtid,直接select wait_for_executed_gtid_set(gtid1, 1)
-- 29.如何检测到主库故障?如何判断一个数据库是不是出问题了?
#有哪些方法可以检测到主库异常?各有什么优缺点?
并发连接数与并发查询数的区别?
业务系统一般也有高可用的需求,在你开发和维护过的服务中,你是怎么判断服务有没有出问题的呢?
-- 30.答疑复习
加锁规则?包含了*两个“原则”、两个“优化”和一个“bug”*
-- 31.误删数据
#误删行怎么恢复?怎么预防?
*delete和truncate / drop table / drop database有什么区别*?
误删表怎么恢复?如何提高恢复效率?
误删实例怎么办?
经历过的误删数据事件?用了什么方法来恢复数据?在这个过程中得到的经验又是什么呢?修改生产的数据,或者添加索引优化,都要先写好四个脚本:备份脚本、执行脚本、验证脚本和回滚脚本。备份脚本是对需要变更的数据备份到一张表中,固定需要操作的数据行,以便误操作或业务要求进行回滚;执行脚本就是对数据变更的脚本,为防Update错数据,一般连备...
-- 32.kill语句
MySQL中有哪些kill命令?
#执行kill命令时,MySQL发生了什么?
如果一个被 killed 的事务一直处于回滚状态,应该直接把 MySQL 进程强行重启,还是应该让它自己执行完成呢?为什么呢?因为重启之后该做的回滚动作还是不能少的,所以从恢复速度的角度来说,应该让它自己结束。当然,如果这个语句可能会占用别的锁,或者由于占用 IO 资源过多,从而影响到了别的语句执行的话,就需要先做主备切换,切到新主库提供服务。切换之后别的线程都断开了连接,自动停止执行。接下来还是等它自己执行完成。这个操作属于我们在文章中说到的,减少系统压力,加速终止逻辑。
-- 33.查询超大量数据
#全表扫描时,server层怎么动作?边读边发
#全表扫描时,InnoDB层怎么动作?如何避免全表扫码占满buffer pool导致命中率下降问题?Buffer Pool,LRU,分两半
如果由于客户端压力太大,迟迟不能接收结果,会导致 MySQL 无法发送结果而影响语句执行。这还不是最糟糕的情况。你可以设想出由于客户端的性能问题,对数据库影响更严重的例子吗?或者你是否经历过这样的场景?你又是怎么优化的?客户端执行*“长事务”*时会对DB产生影响:a.写事务。如果前面的语句有更新,意味着它们在占用着行锁,会导致别的语句更新被锁住。b.读事务也有问题,会导致 undo log 不能被回收,导致回滚段空间膨胀。
-- 34.join语句执行原理
使用join时,被驱动表能走索引时的遍历流程?*能用join吗?怎么选驱动表?*为什么?
使用join时,被驱动表不能走索引时的遍历流程?*能用join吗?怎么选驱动表?*为什么?
调整哪个参数可以增强join性能?
使用join时,什么是小表?
如果被驱动表是一个大表,并且是一个冷数据表,除了查询过程中可能会导致 IO 压力大以外,你觉得对这个 MySQL 服务还有什么更严重的影响吗?还影响buffer pool的young去。具体影响见下一篇。
-- 35.优化join
#范围查询,一个一个回表,可以怎么优化?什么是MRR?排序,变成顺序读
NJL算法可以怎么优化?原理?单个数据回表变批量回表,缓存到join_buffer批量提交给被驱动表,让被驱动表可以进行MRR优化。
BNL算法可以怎么优化?原理?
为了得到最快的执行速度,三表join的索引如何设计?要看join算法。比如如果都是BKA算法,那就是1关联2再马上关联3,得到结果,这样循环
-- 36.用户临时表
临时表是内存表吗?临时表和内存表有什么区别?
分库分表,不走分库key,怎么汇总查询?临时表
临时表在物理上怎么存储?在内存里怎么区分?实现上怎么记录一个线程的内存表?
binlog里会有临时表记录吗?为什么?row方式没有,其他方式会有删除临时表的记录。
备库备份时创建同名临时表会冲突吗?
-- 37.内部临时表,Union和GroupBy
**MySQL中哪些地方用到缓存**?sort buffer、join buffer、buffer pool、update xx......
union用到内部临时表吗?union all呢?
group by语义?执行流程?
内存临时表放不下时怎么办?
*如何优化group by*?分情况讨论?a.加索引:根据group by的key建立索引列,让结果天然有序,无需再用内部临时表排序。b.提示大量数据。此时不会再建立临时表,而是直接走排序让结果有序,然后一一统计。和索引类似。小结里有详细总结。
-- 38.Memory引擎
Memory引擎数据怎么存的?主键索引组织方式?InnoDB引擎呢?
#Memroty引擎有哪些索引?如何支持范围查询?Hash索引,B-Tree索引。数据索引分开存放。数据存数组里。
生产环境可以用Memory引擎吗?为什么?什么情况下可以使用?锁粒度,持久性(主备,双主)。唯一建议使用的就是,用户自建临时表的场景。此时不用考虑并发度,也不用考虑持久性。
生产上有一个内存表,为了避免引备库重启导致备库内存表情况,进而导致主备同步停止。需要将它修改成 InnoDB 引擎表。但是此时业务场景暂时不允许修改引擎,那么可以加上什么自动化逻辑,来避免主备同步停止?
-- 39.自增主键
#自增主键一定是自增的吗?自增值保存在哪里?不同引擎不一样。MyISAM保存到数据文件。InnoDB在5.7版本及之前,保存到内存,每次重启时去找,此时可能会重置自增值。8.0版本后保存到redo log日志。
自增值增长逻辑?指定/不指定具体值时?增长的步长?
自增id能保证是连续的吗?为什么这么设计?唯一索引回滚、事务回滚、批量插入时申请的id会有浪费。
自增锁什么级别?为什么?默认是,普通插入为立即释放,批量插入为语句级别。可以根据参数变更。保证数据一致性。
自增所级别如何设置?binlog为statement时,必须设置为0或1,因为必须保证批量插入的id是连续的,否则statement格式的日志无法精确的记录不连续的id值。binlog为row时可设置为2,即全部立即释放。
自增锁有哪些优化?批量插入时,用语句级别锁,其他时候立即释放。批量插入时,申请id数量随申请次数成指数递增。
在最后一个例子中,执行 insert into t2(c,d) select c,d from t; 这个语句的时候,如果隔离级别是可重复读(repeatable read),binlog_format=statement。这个语句会对表 t 的所有记录和间隙加锁。你觉得为什么需要这么做呢?
-- 40.insert 加锁
insert...select执行时会加什么锁?为什么?
insert批量操作有什么要注意的?唯一性索引有什么要注意的?
你平时在两个表之间拷贝数据用的是什么方法,有什么注意事项吗?在你的应用场景里,这个方法,相较于其他方法的优势是什么呢?
-- 41.最快地复制一张表
快速的复制导入表数据,有哪些方法?各有什么优缺点?
-- 42.grant之后要跟着flush privileges吗
grant 之后真的需要执行 flush privileges 才能生效吗?是立即生效的吗?不用。会同时更新表和内存的。全局级别缓存到会话线程里,db级别在每次use db时重新缓存到会话,表或列级别grant后立即更新权限。
-- 43.分区表
分区表是什么?底层是怎么分割分区表的?分区表优缺点?server层、引擎层
-- 44.答疑
略。
-- 45.自增id
常见的id有哪些?用完怎么办?
Redis - 极客
-- 0.基础体系
Redis使用时会遇到哪些坑?
Redis的整体知识体系?
-- 1.简单内存数据库的总体架构
设计一个简单的KV数据库?需要考虑哪些方面?如何设计?如何实现?应用视角设计,架构层面实现。
和你了解的 Redis 相比,你觉得,SimpleKV 里面还缺少什么功能组件或模块吗?缺少高可用和可扩展的设计
-- 2.Redis数据结构
为什么Redis这么快?内存、数据结构、单线程/网络多路复用、其他改进....
*Redis的value值有哪些类型*?*底层数据结构有哪些类型*?对应关系?有何区别?根据底层数据结构分为两类。实现分别是...
*键值对底层的组织形式*?怎么存的?全局哈希表 -> entry -> key指针,value指针 -> 具体的key值、value值。见图。
Redis哈希冲突时怎么办?rehash怎么操作?
各个结合的底层数据结构?单元素范围操作等不同操作的复杂度?
整数数组和压缩列表在查找时间复杂度方面并没有很大的优势,那为什么 Redis 还会把它们作为底层数据结构呢?内存利用率,数组和压缩列表都是非常紧凑的数据结构,它比链表占用的内存要更少。Redis是内存数据库,大量数据存到内存中,此时需要做尽可能的优化,提高内存的利用率。
-- 3.Redis IO
Redis是单线程还是多线程的?为什么使用单线程?
多线程有什么弊端?单线程有什么问题?为什么用单线程?共享资源竞争消耗资源。accept()和recv()会阻塞,不过可以用OS的多路复用机制解决,底层是由硬件来支持回调的,linux就是select/epoll机制。
*什么是多路复用机制?*阻塞非阻塞、异步同步有何区别?该机制可以用来支持Socket网络模型的非阻塞模式。本质上是*允许一个线程有多个监听套接字和已连接套接字*,并且内核提供监听功能。
Redis请求访问整体流程?画图解答。工作队列?
**详细说说select/epoll模型**?
-- 4.AOF日志
服务器宕机了,如何恢复内存中的数据?
AOF如何实现?有何优缺点?写后日志。优点:可保证命令一定对,且不阻塞当前操作。缺点:先到内存后写日志,宕机时会丢数据。写盘慢时,会阻塞下一个操作。
AOF什么时候写回磁盘?立即写回,写到文件的内存缓冲器后每秒一次写回,写到文件的内存缓冲器后由OS决定协会时机。
AOF日志太大怎么办?重写过程?AOF重写机制。重写是根据值的最新状态生成日志,避免了以前一个数据多次修改的日志,可以缩小日志文件。一个拷贝,两处日志。
AOF 日志重写的时候,是由 bgrewriteaof 子进程来完成的,不用主线程参与,我们今天说的非阻塞也是指子进程的执行不阻塞主线程。但是,你觉得,这个重写过程有没有其他潜在的阻塞风险呢?如果有的话,会在哪里阻塞?fork子进程,fork这个瞬间一定是会阻塞主线程的(注意,fork时并不会一次性拷贝所有内存数据给子进程。fork子进程时,子进程是会拷贝父进程的页表,即虚实映射关系,而不会拷贝物理内存。子进程复制了父进程页表,也能共享访问父进程的内存数据了)
AOF 重写也有一个重写日志,为什么它不共享使用 AOF 本身的日志呢?
-- 5.RDB日志
为什么要用内存快照?AOF数据恢复时,速度很慢。
快照时数据能修改吗?可以,OS只是写时复制。
频繁快照有什么影响?具体使用时怎么配合?Redis4.0,AOF+RDB。
在哪里配置RDB和AOF混合?打开redis.conf 文件,啥都能配。
-- 6.主从模式(读写分离造成的主从延迟怎么解决?)
**Redis的主从模式如何实现**?读写分离。有三种模式,全量复制。基于长连接的命令传播。增量复制。
*Redis的主从模式具体过程*?首次建立连接,3个阶段。
从库太多,导致同步开销太大,阻塞主库,怎么办?主从级联
*主从连接网络断了怎么办*?如何恢复?具体恢复过程?repl_backlog_buffer缓冲区。
Redis设置多大合适?为什么?单个实例几GB,减小RDB开销。
主从库间的复制不使用 AOF 呢?RDB文件内容是经过压缩的二进制数据(不同数据类型数据做了针对性优化),文件很小。而AOF文件记录的是每一次写操作的命令,写操作越多文件会变得很大,其中还包括很多对同一个key的多次冗余操作。
-- 7.哨兵机制
**主库挂了怎么办**?哨兵机制。看主库是不是真的挂了,挂了选哪个从库,新的主库怎么通知给其他从库和客户端。
哨兵用来干什么?监控、选主、通知。
哨兵机制的优缺点?和cluster比?PING命令只能检测主机正常,无法检测Redis正常。
哨兵如何监控主从库已下线?主观下线、客观下线...
哨兵监控如何选主?筛选,down-after-milliseconds配置项。打分,优先级/复制进度/ID号。
-- 8.哨兵集群:由谁执行主备切换
怎么配置哨兵?哨兵如何知道其他哨兵地址?哨兵如何知道从库地址?`“__sentinel__:hello”`频道。INFO命令。
哨兵的消息怎么通知到客户端?
选主结束后,由哪个哨兵来执行主从切换?判断“客观下线”投票。选举Leader投票。都是先投自己一票。
一个 Redis 集群,是“一主四从”,同时配置了包含 5 个哨兵实例的集群,quorum 值设为 2。在运行过程中,如果有 3 个哨兵实例都发生故障了,此时,Redis 主库如果有故障,还能正确地判断主库“客观下线”吗?如果可以的话,还能进行主从库自动切换吗?此外,哨兵实例是不是越多越好呢,如果同时调大 down-after-milliseconds 值,对减少误判是不是也有好处呢?
-- 9.切片集群
切片集群解决什么问题?数据量很大时,不能单纯的加大内存。fork时会阻塞主线程。
简单说说RedisCluster方案?数据存哪里?数据到哪里取?哈希槽,key->哈希槽,哈希槽->Redis实例...
slot数据在迁移时/迁移后,实例slot信息怎么更新?客户端信息怎么更新?直接更新。迁移完成,MOVED命令重定向并更新缓存。迁移到一半,ASK命令告诉实际实例地址,客户端先ASKING,再执行操作命令,本地缓存不更新。
Redis Cluster 方案通过哈希槽的方式把键值对分配到不同的实例上,这个过程需要对键值对的 key 做 CRC 计算,然后再和哈希槽做映射,这样做有什么好处吗?如果用一个表直接把键值对和实例的对应关系记录下来(例如键值对 1 在实例 2 上,键值对 2 在实例 1 上),这样就不用计算 key 和哈希槽的对应关系了,只用查表就行了,Redis 为什么不这么做呢?
-- 10.前9篇问答。
略
-- 11.数据具体存储方式
*一条String记录是怎么存的?占多少字节?*为什么它很费内存?集合类型占多少字节呢?详细分析。SDS多0-9字节(int或SDS),RedisObject多8-16字节(元数据+直接赋值/指针),dictEntry多24-32字节(key,value,next共24字节,总共分配满64字节)。String类型,一个键值对就有一个 dictEntry,多占用24+8 = 32字节的空间。集合类型(list, hash, set, sortedset),一个key可以对应很多条记录。
-- 12.数据结构选择、Bitmap、HyperLogLog
各个统计计算用什么集合合适?聚合计算,Set。
-- 13.海量数据用什么数据结构:GEO
打车场景,需要计算两个位置是否相近,经纬度怎么存?
GEO原理?
如何自定义数据类型?
-- 14.时间序列数据
存储大量的时间序列数据,Redis怎么存?写特点、读特点分析。选型两种方案讲解,Hash+SortedSet,RedisTimSeries。
-- 15.消息队列
Redis可以当MQ用吗?有什么好坏处?用什么数据类型。List,Stream(支持多消费者,提供了ACK功能)。
-- 16.Redis使用异步的地方
Redis单线程还是多线程?哪些地方会阻塞主线程?如何解决?
哪些阻塞点可以异步操作?无法异步操作时怎么避免阻塞呢?
Redis如何实现异步子线程机制?
-- 17.cpu多核对Redis的影响
CPU架构?多Socket、多核、多逻辑核、L1 / L2 / L3。不同的逻辑核共享L1、L2数据,不同的物理核共享L3数据,不同的CPU插槽通过总线连接。
单核或多核的CPU架构,对Redis性能分别有什么影响?可以怎么解决?
网络中断程序和 Redis 实例绑在同一个 CPU Socket 和不同CPU Socket 上有什么区别?
Redis绑到一个逻辑核,有何风险?如何解决?
-- 18.操作使得Redis变慢:慢查询、同时大量删除过期key
怎么判断Redis是真的变慢了?明显的长延迟。基于基线性能的延迟判断。网络延迟用iPerf测下。
*如何诊断Redis变慢?变慢有哪些原因?诊断后如何处理?*即变慢原因、排查方式、处理方式。参考架构图,从Redis自身操作特性、OS系统、文件系统三大方面来判断。
在 Redis 中,还有哪些其他命令可以代替 KEYS 命令,实现同样的功能呢?这些命令的复杂度会导致 Redis 变慢吗?如果想要获取整个实例的所有key,建议使用SCAN命令代替。客户端通过执行SCAN $cursor COUNT $count可以得到一批key以及下一个游标$cursor,然后把这个$cursor当作SCAN的...
-- 19.文件系统和OS对Redis性能的影响
*磁盘性能对Redis的性能有影响吗?为什么?如何解决?*1.持久化为always时,主线程执行,性能也会变慢。2.即使不为aways,是后台执行,但本次执行,仍需要上次执行已结束,否则就会阻塞主线程。
*内存太小对Redis的性能有什么影响?为什么?如何解决?*1.内存太小,Swap操作频繁。2.内存大页,持久化时如果有大量写请求,则会造成大量写时复制,让Redis变慢。
**Redis变慢了,排查思路**?看下9个checklist,结合本篇和上一篇内容做回答。
-- 20.Redis的内存碎片
Redis为什么会产生内存碎片?内因,内存分配器按固定大小分配内存。外因,数据键值对大小不一,以及数据键值对随时在删改。
*怎么看Redis内存碎片?多大算太多?怎么处理*,有哪些配置项?
如果 mem_fragmentation_ratio 小于 1 了,Redis 的内存使用是什么情况呢?会对 Redis 的性能和内存空间利用率造成什么影响?mem_fragmentation_ratio小于1,说明used_memory_rss小于了used_memory,这意味着操作系统分配给Redis进程的物理内存,要小于Redis实际存储数据的内存,也就是说Redis发生swap,严重降低读写性能。
-- 21.Redis缓冲区
Redis内存满了怎么办?
*Redis 内部有哪些地方使用了缓冲区?是怎么设计的?缓冲区溢出有何影响?如何应对?*输入缓冲区、输出缓冲区、复制缓冲区(全量复制,用来临时存主节点写命令)和复制积压缓冲区(增量复制,环形区域,用来存发送给从节点的命令数据,从节点断连后重连时,可快速恢复)
-- 22.前文总结提问
略。
-- 23.只读缓存和读写缓存
你们Redis缓存是怎么用的?只读还是读写?有什么区别?
Redis 的只读缓存和使用直写策略的读写缓存,都会把数据同步写到后端数据库中,它们有什么区别吗?当有缓存数据被修改时,在只读缓存中,业务应用会直接修改数据库,并把缓存中的数据标记为无效。在读写缓存中,业务应用需要同时修改缓存和数据库。
-- 24.缓存淘汰策略
设置多大的缓存合适?怎么设置?根据长尾分布和重尾分布原理,以及具体业务,设置15%-30%。
*Redis有哪些数据淘汰策略*?LRU算法是什么?Redis怎么实现的?Redis进行了一个简化,加了一个随机选取候选集合的操作。
-- 25.缓存和DB不一致问题
*什么时候会发生缓存不一致的情况?*如何处理?分两种模式讨论,读写缓存(同步直写保证原子性,异步写回没法避免)、只读缓存(保证写时原子性删除缓存记录)。
如何解决数据不一致问题?*缓存和DB操作都成功,有可能数据不一致吗*?事务。重试机制。
-- 26.缓存雪崩、缓存击穿、缓存穿透
*什么是缓存雪崩、缓存击穿、缓存穿透?如何应对*?
缓存雪崩可以采用服务熔断、服务降级、请求限流的方法来应对,那么这三个机制可以用来应对缓存穿透问题吗?
-- 27.缓存污染-淘汰策略
八个淘汰策略,哪些可以解决缓存污染问题?
LFU对比LRU,改进了哪些地方,解决了什么问题?LRU单次扫描查询问题。LFU增加了次数纬度。次数使用非线性递增(8位只有255),同时设置了自动衰减(短期内大量访问后不再访问)。
使用了 LFU 策略后,你觉得缓存还会被污染吗?1.被污染的概率取决于LFU的配置,也就是lfu-log-factor和lfu-decay-time参数。2.访问次数衰减期间,是污染的。
-- 28.Pika(省略一部分)
*Redis单个实例存太多数据会有什么问题*?
-- 29.无锁原子操作:简单命令、Lua脚本
*Redis怎么处理并发访问*,以防止脏数据?两种方法。原子性操作、加锁。
*Redis的原子操作怎么实现*?简单操作:INCR / DECR单命令。复杂操作:Lua脚本。
代码中怎么用?
-待补充- 30.Redis分布式锁:重点,待补充
-待补充- 31.Redis实现事务:待补充
-- 32.主从延迟
Redis主从数据不一致是什么原因?如何解决?**如果一定要保证强一致性呢**?
读到过期数据是什么原因?如何解决?
我们把 slave-read-only 设置为 no,让从库也能直接删除数据,以此来避免读到过期数据,你觉得,这是一个好方法吗?主从复制中的增删改都需要在主库执行,即使从库能做删除,也不要在从库删除。否则会造成数据不一致。
-- 33.脑裂
脑裂会导致数据丢失吗?
怎么防止主库被占满而产生假故障而造成哨兵误判?做好两个配置项,让老主库在主从切换期间暂停接收客户端请求。
假设我们将 min-slaves-to-write 设置为 1,min-slaves-max-lag 设置为 15s,哨兵的 down-after-milliseconds 设置为 10s,哨兵主从切换需要 5s。主库因为某些原因卡住了 12s,此时,还会发生脑裂吗?主从切换完成后,数据会丢失吗?
-- 34.第23~33讲
略
-- 35.Codis
Codis的整体架构?客户端请求访问流程?客户端 -> proxy -> server
Codis的数据怎么分布的?slot分布。和RedisCluster的区别时,一个从proxy中心获取路由,一个每个实例分布式保存路由。
Codis集群扩容时如何做?proxy扩容,直接扩。server扩容,同步迁移 / 异步迁移。
Codis集群可靠性如何保证?server、proxy/zookeeper、dashboard/fe。
Codis和RedisCluster如何选择?成熟稳定、单例客户端(Codis直接访问proxy,跟单例一样)、新特性、数据迁移性能(Codis支持异步迁移)。
假设 Codis 集群中保存的 80% 的键值对都是 Hash 类型,每个 Hash 集合的元素数量在 10 万~20 万个,每个集合元素的大小是 2KB。你觉得,迁移一个这样的 Hash 集合数据,会对 Codis 的性能造成影响吗?不会有性能影响...
-- 36.Redis支持秒杀
如何使用Redis支持秒杀场景?秒杀前,无需Redis,CDN即可。秒杀中,查询库存 -> 扣减库存 -> 订单操作,前两步需要Redis,且需要保证两步操作的原子性(原子性操作或分布式锁)。秒杀后:已买用户查订单,未买用户查有没有退单,正常流量,服务端能够支撑。
分布式锁有什么用?例如,Redis原子性操作,不想用Lua脚本时。
假设一个商品的库存量是 800,我们使用一个包含了 4 个实例的切片集群来服务秒杀请求。我们让每个实例各自维护库存量 200,然后,客户端的秒杀请求可以分发到不同的实例上进行处理,你觉得这是一个好方法吗?使用切片集群分担秒杀请求,可以降低每个实例的请求压力,前提是秒杀请求可以平均打到每个实例上,否则会出现秒杀请求倾斜的情况,反而会增加某个实例的压力,而且会导致商品没有全部卖出的情况。
-- 37.数据倾斜
什么是数据倾斜?有哪些原因?如何应对?
在有数据访问倾斜时,如果热点数据突然过期了,而 Redis 中的数据是缓存,数据的最终值保存在后端数据库,此时会发生什么问题?此时会发生缓存击穿,热点请求会直接打到后端数据库上,数据库的压力剧增,可能会压垮数据库。
-- 38.Redis cluster规模受通信数据影响
RedisCluster的实例之间通过什么通信?Gossip协议。
RedisCluster最多可以运行多少个实例?跟通信开销有关。Gossip协议、通信消息大小、通信频率。
如果我们采用跟 Codis 保存 Slot 分配信息相类似的方法,把集群实例状态信息和 Slot 分配信息保存在第三方的存储系统上(例如 Zookeeper),这种方法会对集群规模产生什么影响吗?因为集群的信息保存在了第三方存储系统上,意味着redis cluster内部不用再沟通了,这将节省下大量的集群内部的沟通成本。当然就整个集群而言部署、维护也会更加复杂,毕竟引入了一个第三方组件来管理集群。
-- 39.Redis 6.0 新特性
Redis6.0的新特性有哪些?执行流程?怎么使用?
Redis 6.0 的哪个或哪些新特性会对你有帮助呢?Redis 6.0 提供的多 IO 线程和客户端缓存这两大特性,对于我们使用 Redis 帮助最大。
-- 40.基于NVM内存的Redis
什么是NVM?怎么使用?
有了持久化内存后,还需要 Redis 主从集群吗?肯定还是需要主从集群的。持久化内存只能解决存储容量和数据恢复问题,关注点在于单个实例......
Spring - Spring揭秘
-- 第2章 IOC基本概念
IOC有几种注入方式?分别举例说明?构造方法、setter方法、接口方法。其实就是在哪里赋值而已。
**IOC解决了什么问题**?为什么要有IOC?封装复杂依赖,实现多态,便于单元测试。1.创建了大量重复对象,造成大量资源浪费。2.更换实现类时,要改动很多地方。3.创建和配置组件的工作是很繁杂的,组件调用方用起来很麻烦。这一切问题,就是因为Bean的构建和使用没有解耦。所以IOC用来解耦Bean的创建/生命周期管理和使用。扩展:AOP则解决了切面逻辑编写繁琐,有多少个业务方法就要写多少次的问题。是面向对象的补充。
IOC容器需要解决什么问题?创建对象,管理依赖。
-- 第3章 IoC 容器应该完成哪些工作
IOC容器管理依赖关系有哪些手段?或者说有哪些描述手段?直接编码、xml配置、注解。
Spring提供的IOC容器有哪些?Bean Factory和ApplicationContext
-- 第4章 Spring的IoC容器之Bean Factory
配置文件 -》 BeanDefinition -》BeanWrapper -》Aware -》BeanPostProcessor -》InitializingBean / init-method -》BeanPostProcessor-》DisposableBean / destory-method
Bean Factory是什么?Spring提供的IOC容器之一,提供最基本的IOC容器服务,默认采用lazy-load,所以启动也快。对象用到的时候才会生成及绑定。
ApplicationContext是什么?Spring提供的另外一个IOC容器。继承至Bean Factory的两个子类,外加扩展另外3个接口。两者关系见图4-2。
怎么使用BeanFactory获取对象?如何把对象注入到BeanFactory?1.在xml配置Bean实现依赖管理,2.初始化`BeanFactory`(如`BeanFactory container = new XmlBeanFactory(new ClassPathResource(String xmlPath)));`),3.然后直接从`BeanFactory`拿bean即可(`container.getBean("djNewsProvider");`)
BeanFactory怎么保存对象注册也依赖信息?直接编码、配置文件(xml或properties)、注解
BeanFactory接口?BeanDefinitionRegistry接口?BeanDefinition接口?BeanDefinitionReader接口用来干什么?它们有哪些实现类?*DefaultListableBeanFactory*
外部配置文件里描述的Bean如何注册到BeanFactory容器里?*文件 --> BeanDefinitionReader ---BeanDefinition---> BeanDefinitionRegistry --> BeanFactory*
想要用自定义格式的文件来描述Bean,怎么做?实现BeanDefinitionReader接口,自己管理文件描述约定、类的加载(?)、BeanDefinition的生成、以及BeanDefinitionRegistry的注册。
注解描述的Bean如何注册到BeanFactory容器里?Bean的扫描注入工作由扫描器完成,在Spring的配置文件里加入并设置好BasePackage。具体原理后续具体分析。
spring的XML文件由哪些元素构成?
beans元素有哪些属性?有哪些元素?各有啥用
bean有哪些属性?
如何表达bean元素之间的依赖?构造方法注入:声明Bean的构造方法参数\<constructor-arg\>。setter方法注入:声明Bean的属性字段\<property\>。
有哪些可以用于构造方法注入和setter方法注入的元素类型?几乎都可以呀老铁,null,ref,bean,list,map......
autowire有哪些自动绑定模式?byType和byName有什么区别?其他模式呢?都可以用于构造方法注入和setter方法注入...
bean有哪些作用域?各有什么区别?单例/多例,加上3个专门用于web的作用域。或:对于bean的scope属性,singleton、prototype,request、session、global session各有什么区别?
singleton属性的bean有几个?生命周期?和Singleton模式有啥区别?spring默认的scope是什么?
自定义scope怎么玩?
关键词:BeanDefinitionReader,BeanDefinition,BeanDefinitionRegistry ,BeanFactory,FactoryBean...
静态工厂方法、非静态工厂方法、FactoryBean怎么注入Bean??
怎么用方法注入获取bean?怎么用BeanFactoryAware获取bean?怎么用ObjectFactoryCreatingFactoryBean获取bean?
怎么用org.springframework.beans.factory.support.MethodReplacer接口替换方法逻辑?
设计一个系统,主要有哪些方面?配置类,容器类,工具类,主逻辑。
容器从元数据变成对象,整个流程?经历了哪两个阶段?启动阶段,实例化阶段。
容器启动阶段的扩展点?BeanFactoryPostProcessor
-- 第5章 ApplicationContext
ApplicationContext在BeanFactory功能的基础上主要进行了哪些扩展?
Spring提供的BeanFactory有哪些?ApplicationContext实现有哪些?
为什么要自己定义资源加载策略?
如何描述资源?有哪些实现类型?
如何定位资源?有哪些实现类?批量定位用哪个?定位的逻辑顺序?ResourceLoader接口,实现类有DefaultResourceLoader、FileSystemResourceLoader、FileSystemXmlApplicationContext、ResourcePatternResolver
AbstractApplicationContext抽象类作为ResourceLoader接口或者ResourcePatternResolver接口时,使用的具体是哪两个类?见继承关系图
对于两个容器,Bean如何注入ResourceLoader、Resource?
不同ApplicationContext实现的的Resource的加载行为有何不同?
JavaSE用哪两个类提供国际化支持?Spring呢?ApplicationContext实现了哪个MessageSource?为何要实现?
ApplicationContext底层的事件发布原理?如何实现JavaSE的自定义事件发布?发布订阅者模式,EventObject、EventListener。
Spring容器内的事件发布,涉及哪些类?如何进行应用?见5.3
-- 第6章 通过注解使用IOC
@Autowired和@Resouce注解什么区别?它们各自搭配的BeanPostProcessor是什么?
@Qualifier用来做什么?
BeanPostProcessor可以怎么统一配置?
-- 第7章 AOP概念
AOP用来做什么?应用举例?
AOL是什么?AspectJ是什么?织入是什么?
*AOP有哪些实现方式*?动态静态有什么区别?优缺点?静态AOP,逻辑用AOL语言描述,用特定编译器,以java字节码形式,融合到class文件。动态AOP,类加载或系统运行期间,动态操作字节码。
*AOP在哪些时候可以织入*?Java代码生成,编译期织入(aol文件+专门的编译器),类加载期(自定义类加载器类加载期),运行期织入(动态字节码增强,动态代理)
AOP有哪些概念?连接点Joinpoint执行点、切入点Pointcut要切入的连接点集合、增强Advice执行逻辑、切面Aspect包含多个Pointcut/Advice、织入。
-- 第8章 AOP底层原理
静态代理?怎么实现?
**动态代理?怎么实现?哪些Api?手动写一个?**Proxy.newProxyInstance(类加载器,被代理对象接口,InvocationHandler增强)生成动态代理对象。InvocationHandler接口实现invoke方法。
**动态字节码生成?怎么实现?哪些Api?手动写一个?**用enhancer对象设置父类class、callback两个字段后,直接调用create()来生成新的代理对象。实现Callback或`MethodInterceptor`接口的intercept()方法来封装增强(methodProxy.invokeSuper()调用原始方法)。
-- 第9章 Spring是如何实现AOP的
AOP的实现机制?涉及哪些类?如何实现?
-- 第10章 注解类AOP的实现
注解形式AOP的实现机制?
多个Advice匹配到同一个方法,它们执行的优先级如何确定?同一个Aspect内按声明顺序。不同Apsect,按Ordered接口。
Aspect是单例的吗?
-- 第11章 AOP应用案例
异常处理
安全检查
Java异常谱系?
拦截器和过滤器有什么区别?
AOP有哪些典型应用场景?
-- 第12章 类内方法A调用方法B,方法B的AOP失效的问题
**类内方法A调用方法B,方法B的AOP失效,原因是什么?如何解决?**
没走代理。在目标对象中使用`AopContext.currentProxy()`显示指定代理方法即可。
-- 第13章 Spring 统一的异常封装
为什么需要Spring统一数据访问异常体系?解决了什么问题?异常不能不让客户端知道,又不能作为受检异常让客户端去具体处理。综上,只能全部封装分类为标准的非受检异常抛出,同时根据不同的RDBMS实现厂商,将各厂商的异常统一处理归类到标准非受检异常,再抛出给客户端,这个工作就由Spring来完成。
-- 第14章 Spring提供的JDBC最佳实践
为什么要有JdbcTemplate?1.原始的JDBC贴近底层,编码冗余难用。2.原始的JDBC异常很难分析,异常类型和厂商耦合到一起,所有异常集成到一个SQLException,具体异常根据ErrorCode判断,而ErrorCode又由各个厂商去判断。
JdbcTemplate如何实现?模板模式 + CallBack逻辑封装。模板模式规定执行路径。再优化抽象方法,改为执行逻辑用CallBack接口从方法参数即可。有DataSource和SQLExceptionTranslator属性,有XXXX类模板方法。
SQLException是什么?JDBC的统一抛出异常,根据errorCode对应具体异常。而errorCode又由各个厂商自行规定,导致了SQLExcetion没能和具体厂商解耦。
DataSource和DraviManager有什么区别?javax.sql.DataSource。JDBC 2.0引入,用于替代基于java.sql.DriverManager的数据库连接创建方式。DataSource可看做是作JDBC的连接工厂,可以引入对数据库连接缓冲池以及分布式事务的支持。Spring数据访问层对数据库资源的访问,全部建立在javax.sql.Datasource标准接口之上。
怎样实现自定义的DataSource?Spring事务是怎么操作DataSource的?
-- 第15章 Spring 对 MyBatis的集成
MyBatis和JDBC什么关系?
Spring集成ORM主要解决了什么问题?统一的数据访问方式,统一的异常处理体系,统一的事务控制体系。
Spring如何集成iBatis? SqlMapClientTemplate + SqlMapclientCallback
-- 第16章 其他类似模式的使用
模板方法设计模式 + CallBack 的经典设计模式由哪些运用?
-- 第17章 事务特性
事务的ACID特性?以及对于I的4个隔离级别区别?MySQL底层实现?
分布式事务常见实现方案?2PC,TCC事务补偿(阿里的框架),本地消息表(FaceBook),RocketMQ(基于可靠消息的最终一致性),最大努力通知。
-- 第18章 原生的以及其他厂商的事务控制
原生事务管理怎么做?缺点?直接拿具体数据访问厂商的API。事务和业务代码耦合在一起,很混乱。没有统一的异常处理。没有统一的API。单机的事务Java没有原生了,靠各个数据访问厂商提供。分布式的提供了JTA和JCA。
-- 第19章 Spring的事务实现
**Spring事务框架实现的核心思路**?1.PlatformTransactionManager,TransactionStatus,TransactionDefinition。2.(1)核心是在TransactionManager要把connection存下来,然后所有事务操作用同一个connection来操作(用ThreadLocal的方式实现)。(2)不想用它的话,可以用`DataSourceUtils`替代。Spring提供的事务支持的时候,就是通过DatasourceUtils来获取连接(3)可以用形参在方法间传导connection的方式,不过太蠢,而且跟具体的connetion耦合了。3.另外,Spring数据访问框架的DataSourceUtils提供了获取同一个connection的逻辑,所以我们都要用他。
Spring事务架构涉及哪些接口?各用来干啥?如何实现?
事务传播机制是解决什么问题的?有哪些?https://blog.csdn.net/weixin_39625809/article/details/80707695
DataSourceTransactionManager怎么实现的?如何判断事务传播机制?提交后做哪些处理?
-- 第20章 如何使用Spring事务
Spring声明式事务怎么实现?TransactionDefinition等元数据存到哪?怎么存?存XML或者@Transactional注解里。拦截下,底层直接用transactionTemplate编码实现。
@Transactional注解底层如何实现?TransactionTemplate + CallBack。
-- 第21章 活用ThreadLocal、Strategy模式
**ThreadLocal用来做什么?实现原理?**获取当前线程的threadLocals变量,然后以自己为key,存入变量。
ThreadLocal应用场景?
策略模式在Spring使用的示例?
-- 第22章 Servlet
MVC指的是什么?Servlet + JSP + JavaBean
SpringMVC的演进?单一的Servlet -> JSP Model 1:JSP + JavaBean -> JSP Model 2:Servlet + JSP + JavaBean -》Web框架:抽出硬编码,Servlet单一的控制器 + 次级控制器。
-- 第23章 整体MVC流程
**SpringMVC怎么处理一个请求?**见各角色交互图。同时参照第25章两个图。
-- 第24章 SpringMVC详细流程
*细说SpringMVC处理流程*?文件上传、Handler适配器、Handler拦截器、Handler异常处理、国际化、主题...
-- 第25章 其他组件支持
要想增加新的Handler,怎么实现?
拦截器可以在哪些地方拦截?*如何实现一个自定义的拦截器*?
*拦截器和过滤器有什么区别*?如何配置过滤器?
-- 第26章 基于注解的controller
怎样实现基于注解的Controller功能?
SpringMVC用于处理注解的类?DefaultAnnotationHandlerMapping,AnnotationMethodHandlerAdapter。
请求参数如何进行数据绑定?特定类型...,非特定类型...
-- 第27章 Spring MVC扩展
略
leetcode面经汇总
1.3年工作经验,双非裸辞社招面经 【已入职百度】
成都IT内推圈-老农L3发起于 2021-03-10
##### 58 一面 40min 挂
**自我介绍**
1. 离职原因?为什么这个时候离职?
2. http1.1 http1.0 http2.0 区别
3. redis长度过长怎么优化?哪个api,数据量超过多少效率会变低?
4. MySQL做过哪些优化?覆盖索引?limit两个参数区别?MySQL分页优化的其他方法
5. concurrenthashmap如何保证线程安全,说说你的理解
6. arraylist linkedlist 使用场景
7. 本地线程和守护线程的区别,Thread.setDemon();
8. 线程状态
9. 线程池参数?线程池为什么用new的不好?
10. 项目:前台如何调后台接口?rpc?主服务项目多大
11. 有什么问我的?
12. 目前薪资 期望薪资?
13. 鼓励
##### 字节跳动 一面 78min 过
**自我介绍**
1. 你对全栈的理解
2. 离职原因,为什么这个时间离职
3. 技术上没有学到东西吗?
4. 哪块儿比较熟?
5. synchronized?mute lock怎么实现的
6. Java看过哪些源码?线程池好处?多创线程就怎么了?压测的时候创建几千个线程才几毫秒这点儿开销有必要节省吗?内存开销,时间开销?线程池参数,execute执行流程,work?没有工作会删除吗?睡眠状态?idl怎么配置的?最大线程满了之后?
7. 有哪些Map?还有啥Map?用的jdk几?说一下HashMap数据结构,put值散列冲突怎么解决?链表树化转移数量?为什么是8为什么是6??为什么数组要是二次幂?怎么扩容的?扩容rehash的流程?
8. concurrentHashMap的散列流程?concurrentHashMap怎么实现的线程安全?CAS什么意思,怎么实现的?Unsafe怎么实现?concurrentHashMap什么时候用到CAS?并发情况下两个线程都到之后怎么插入的?初始化的时候两个线程都检测到需要初始化了,然后怎么做的?
9. 算法题 coins硬币 / 一句都没写出来,做了20min白卷交的,(我:该用动态规划做,但不知道怎么下手了,面试官:转移方程怎么写?我:对不起,忘记了)
10. 怎么学习的?
11. 最常看的博客?网站?
12. 有什么好书?技术和非技术都行
13. 怎么看待学习和看书?
14. 你有什么问我的?
o 我进入您的部门哪方面需要提高?
o 大概什么时候出结果?
##### 字节跳动 二面 30min 没算法题 挂
「忘记录音了,只记得这些了」
**自我介绍**
1. 为什么离职?
2. 你觉得自己有什么可以拿出来讲的点吗?
3. 你做的主要工作有什么?最复杂的一个业务讲一下流程?
4. 并发度提100倍有哪些优化的点?
5. 限流怎么做的?令牌桶的算法实现?限流还有哪些方式?
6. 接口450ms 优化到了 360 ms怎么优化的?
7. tomcat只是修改了一下参数吗?
8. redis集群部署方式?主从和哨兵的区别?
9. 缓存方式还有哪些?
10. redis数据结构,string底层实现,跳表复杂度?
11. redis使用过程中出现过变慢的情况吗?
12. nginx后面的形态是怎么样的?
13. 网关层还了解什么技术?
14. 对自己的定位,技术发展?
15. 别人对你的评价?
16. 你有什么问我的?
##### 流利说 一面 40min 过
**自我介绍,项目 20 min**
1. 单点故障怎么解决?添加节点自动化还是手动?提升系统负载能力怎么测的??
2. http 1.0 1.1区别?
3. 并发并行区别?
4. 并发数达到了400多怎么做的优化?
5. 缓存穿透?其他请求如何知道值已经到缓存中了?
6. 锁怎么做的?分布式锁怎么做的?放过去的请求失败或者延迟大量请求阻塞在那里怎么办?
7. 日志记录模块讲一下?日志统一记录?
8. 可用性怎么保证的?报警怎么实现的?报警的指标只是健康检查?
9. 服务之间的相互调用有涉及到吗?分布式链路追踪如果某个服务调用出问题了,怎么排查问题?
10. https协议目标源是静态文件,按回车整个请求链路?http静态文件和接口请求的区别?对CDN有了解吗?https加密是对称还是非对称?
11. SQL调优你会怎么做?索引的数据结构?MYSQL的事务有哪些?比较常用的是哪些?
12. 常用的Linux命令一直说,直接说命令的名字
13. Java转golang怎么看?
14. 你想问我?
14号线下进行后续3轮面试。「已拒」
##### 百度 一面 50min 过
**自我介绍**
1. 关键SQL优化怎么优化的?为什么性能不好?主键必须有吗?数据索引密集度很差的话,你的优化意义不大吧?
2. MySQL有哪几种索引?聚簇索引和辅助索引的区别?索引数据结构?为什么用B+树?
3. MVCC?版本号怎么变化的?更新的数据的时候怎么确定版本的?幻读怎么解决的?
4. 一个SQL怎么走的索引?MYSQL会怎么选的?MySQL哪些不正规的写法无法命中索引?
5. MySQL有哪几种日志?redo log主要有什么用?提交之后100%落盘吗?为什么MySQL要写到redo log buff内存?
6. redis一般怎么用的?为什么选择用redis?为什么redis快呢?
7. redis几种数据类型?redis string的底层实现?
8. 分布式锁用过吗?说说怎么用的?用的哪个命令?
9. redis 底层 hash 表扩容机制说一下?
10. 类加载过程?常用的类加载器?调用顺序?为啥双亲委派?
11. mq重复消费,丢消息的问题怎么解决?redis的list有哪几种操作?布隆过滤器特点?缓存穿透?
12. static关键字的用法?
13. 用到的数据结构那些?Map put的流程讲下
14. kafka,zookeeper了解吗?
15. ThreadLocal用过吗?不remove掉会有什么问题?
16. 口述算法:之字打印
17. 有什么问题?
##### 百度二面 68min 过
**自我介绍**
1. 哪个项目时间长一些,两个项目技术栈都讲一下,详细介绍一下***项目具体做了哪些事情,一些查询维度的接口?如果现在让你开发一些接口,你怎么做接口隔离。表的数量?表数据量?
2. SQL优化介绍一下做了哪些?怎么替换?
3. 限流怎么做的?解释一下
4. 介绍一下另一个平台。按刚才的介绍方式。
5. redis解决客户端session共享信息怎么解决的。
6. redis分布式锁解决了什么问题?
7. redis为什么能支持分布式锁?使用方式有哪些?
8. MQ用在业务场景?MQ本身的优势是什么?一般什么情况下可以使用这个技术?核心本质原因是什么呢?开线程做不就可以了区别是什么?
9. zk,kafka
10. 你们的总线讲一下?
11. Spring循环依赖怎么解决?
12. 让你写一下堆栈溢出你怎么写?为什么往集合设置那么多元素没有被GC?
13. 介绍一下Java的锁?
14. 你看这些源码自己的理解是什么?介绍了线程池execute,submit中适配的思想
你有什么问我的?10min
##### 百度3面 36min 过
**自我介绍**
1. 写博客原因?
2. 离职原因?
3. 为什么裸辞?
4. 还有哪些再看的机会?
5. 长期规划?
6. 你最大的优势?
7. 你怎么学习一个技术?
8. 你如何实现一个短期目标?
9. 还有什么问我的?
「流程快到没朋友」,三面完半小时发来了测评,三面完一个小时发来了材料准备的邮件。
##### 搜狐 1 面 64min 过
**自我介绍**
1. 有其他offer吗?
2. tcp三次握手,四次挥手为什么是4次?
3. http1.0 1.1 2.0?
4. redis 分布式锁的实现方式?
5. redis 数据结构有哪些,zset 底层数据结构是什么,讲一下?
6. == equals区别,如果hashcode相等代表equals相等吗?
7. hashmap底层实现方式『tableSizeFor,hash』?
8. 1.8相比1.7为什么头插变尾插?
9. 线程安全的map有哪些?为什么用concurrenthashmap?底层实现是什么?
10. 什么时候变成红黑树?双哈希表?「这些其实讲到了源码层面,initTable,resize,tryPresize,Thread.yield,ForwardingNode。」
11. volatile讲一下,MESI?
12. Spring IOC,AOP你的理解讲一下?
13. Spring注入方式知道哪些?
14. bean是线程安全的吗?
15. 缓存穿透,雪崩,击穿讲下你的理解。雪崩问题的解决方案?
16. 实际场景提:活动页面,对于该页面数据有些用户本身没有缓存,有些用户有对应缓存。参加活动了的用户才有缓存,来了大量请求如何确保用户的请求正常返回。
17. Innodb,memory区别?聚簇索引,非聚簇索引区别?B树,B+树区别?innodb还有什么索引?回表操作再走一遍主表吗?什么情况下不走?
18. 4种事务隔离级别和分别的问题?
19. Linux命令用的多吗?awk用过吗?
20. SQl调优你怎么做的?
21. Java垃圾收集器知道哪些?高并发情况下用哪个?
22. 算法:二叉树中序遍历,递归非递归实现
23. 写一下单例模式
24. 有什么问我的?
. 哪里需要提高?
. 框架仅停留在使用层面-14,15,16题
. 业务上思考的少-16题
. 部门技术栈?
. 部门所做业务?
. 后续面试流程?-1年多经验两轮技术面。
腾讯丨java丨社招丨面经
[面经熊L4](https://leetcode-cn.com/u/agitated-grothendieck2ro/)发起于 2021-05-02
【一面】
1、mysql索引结构?
2、redis持久化策略?
(1)RDB:快照形式是直接把内存中的数据保存到一个dump的文件中,定时保存,保存策略。当Redis需要做持久化时,Redis会fork一个子进程,子进程将数据写到磁盘上一个临时RDB文件中。当子进程完成写临时文件后,将原来的RDB替换掉。
(2)AOF:把所有的对Redis的服务器进行修改的命令都存到一个文件里,命令的集合。使用AOF做持久化,每一个写命令都通过write函数追加到appendonly.aof中。aof的默认策略是每秒钟fsync一次,在这种配置下,就算发生故障停机,也最多丢失一秒钟的数据。缺点是对于相同的数据集来说,AOF的文件体积通常要大于RDB文件的体积。根据所使用的fsync策略,AOF的速度可能会慢于RDB。Redis默认是快照RDB的持久化方式。
3、zookeeper节点类型说一下;
4、zookeeper选举机制?
5、zookeeper主节点故障,如何重新选举?
6、syn机制?
7、线程池的核心参数;
8、threadlocal的实现,原理,业务用来做什么?
9、spring di的原理;
10、四次挥手;
11、gcroot选择;
12、标记清除算法的过程,标记清楚算法如何给对象分配内存空间?
13、cms算法的缺点;
【二面】
1、correnthashmap?
2、threadlocal原理?
3、hashmap;
4、Java数据类型,同步机制;
5、讲讲贪心算法;
6、如果线上用户出现502错误你怎么排查?
7、并发量很大,服务器宕机。你会怎么做?
【三面】
1、syn和lock的区别,哪个更好?怎么选择?
2、hashmap源码,为什么8个节点变成红黑树 又为什么到了6个节点才恢复为链表?
3、缓存穿透,怎么解决?
4、负载均衡算法,实现;
5、轮询和随机的缺点;
6、分布式服务治理;
7、dns迭代和递归的区别;
8、为什么连接的时候是三次握手,关闭的时候却是四次握手?
因为当Server端收到Client端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当Server端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉Client端,"你发的FIN报文我收到了"。只有等到我Server端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送。故需要四步握手。
想看更多互联网大厂面试经验的同学可以戳链接https://mp.weixin.qq.com/s/cHWtErbwnrmtB3Gg3Isv2Q
关注公众号【面经熊】回复面经还可以获取互联网大厂求职面试大礼包,包含各个岗位的面试经验,助你上岸!
【后端面经】字节跳动 |深圳后端高级开发岗|热乎凉经|2021|
## 一面:时间5月10号 20:00
1.项目相关(我是做支付交易相关的,刚好面的也是支付部门)
其中有个问题:① 热点账户如何解决的;② 只出账户拆分成多个子账户,那某个子账户进行扣减的时候,该子账户钱不够了怎么办?
2.如何解决资源竞争激烈问题,转换一下问题就是并发场景下如何提升性能。说我使用java,那就已java语言为例,说说你使用的
说了:乐观锁、悲观锁(java各种锁相关,不过字节不是java,所以没有详细说,大概说了下思路),这个主要还是往如何在并发场景下提升处理性能,两个大方向:
① 尽量实现不共享数据,并发线程独享(然后提了threadLocal)
② 如果无法避免共享,首先可以考虑选择CAS + 自旋(乐观锁,竞争不是非常激烈的场景适用), 加同步锁场景下尽量:减少锁粒度、锁时间、拆分共享数据(和上面的热点账户解决方案对应)
3.MySQL相关
① 各事务隔离级别,每种隔离级别区别、能解决什么样的问题
② 可重复读隔离级别如何实现的
③ redo log 和 undo log 区别和作用,保存的内容
④ 项目中是否参与过表设计,在进行表设计时,你会考虑哪些方面?(尽量多说自己的考虑) 比如创建索引(普通索引、联合索引、唯一索引)该考虑哪些、如何给大字段创建索引等等,尽量多说,不过要说好这个,还是得先学好MySQL底层的一些原理,再加上实践
4.Redis 中如果某个请求命令响应比较久,会是哪些原因
我的回答:① 可能命令本身涉及的数据操作耗时有些高(bigKey查询、聚合运算)
② redis服务刚好在RDB持久化(bgsave 时,主线程fork子进程也是会被阻塞的,redis实例保存的数据量越多,阻塞时间越久)
③ 可能出现网络环境拥堵
写面经的时候想到的:
④ 可能请求命令到达了redis,但是由于redis单线程处理命令机制,该命令前面有其他的大的事务、bigkey等耗时的命令在处理
⑤ bgrewriteaof AOF日志重写(如果开启了的话),也是需要主线程fork子进程
5.算法:力扣155最小栈的小改版,getMin换成getMax,可能前面面的久,就出了一道题,刷过的,忘记了,再加上面试有些紧张把getMax实现想多了,然后面试官帮忙分析和指引,最后是做出来了
一面总结:暂时记得这些,问的基础的都是自己会的,而且在团队内做过分享的,但是回答的时候因为有些紧张(今年没面过,直接来面字节了,没有先试试手)答不是很顺,面试时长 1h10min 左右
## 二面:时间5月11号 20:00 牛客视频
先大概总结下:范围不广,但是相对问的比较深!基本没聊项目 总共面了 1h20min
1.开始就来框架 (这是我目前近一年多学习最少的,基本没有学习框架源码之内的),spring中的bean的生命周期等(这个面试官应该之前java转来的,前面问了很多java相关的,哎~本以为不会怎么问java相关的
2.java中的concurrenthashmap 1.8的有什么新的特性(答得不全、之前看了,忘记了,最近备战真没怎么看java源码相关的,之前知道的也都忘了差不多了)
3.如何将非常多的数据高效快速的插入到concurrenthashmap中?
我答得是初始尽量开辟可预知的初始容量,避免频繁扩容、如果实在无法避免,就改造扩容机制(采用和redis一样的渐进式扩容机制),然后面试官说还有呢?其实一直往改造concurrenthashmap的方向在想,然后实在想不出了,让面试官给点提示,然后面试官提到使用多线程(….这….我内心感觉这不是必须的吗?concurrenthashmap能保证线程安全)
但是又接着问说多线程情况下,即使锁粒度再小,也会存在同步竞争问题,这种情况怎么办,性能还是会有影响(脑袋一时间空白,事后分析想到应该是想让我说出1.8加入的CAS,自旋+CAS在竞争的时候不会使线程状态转换,如果用锁方式会使线程释放CPU进入到阻塞等待态,这就意味着会有线程上下文切换,带来性能上的影响)
4.零拷贝了解吗,什么原理,什么场景下会使用,说了基本流程(被面试官说不够细,有点粗)和零拷贝使用场景,但是面试官问的细,说你没有说到磁盘数据如何到的内核缓冲区(DMA)、到内核缓冲区后如何通知CPU(软中断)等等,看过,主要是忘记了,在面试官来看不够透彻,总结不够
5.数据库:什么场景下索引会失效:显示函数、隐式函数转换、索引值区分度不够优化器最终不会选择、数据量少的时候、模糊查询没有使用到前缀原则、not null(就提了这一个问题,数据库还好,二面面试官说一面面试官反馈我数据库方面不错,所以二面面试官直接说了不会怎么提数据库了)
6.分布式事务两阶段提交存在的问题、三阶段提交又是什么,解决了什么问题?(其实之前学架构专栏的时候,思考过,奈何时间久了,事后才想起来)
7.RocketMQ 分布式事务实现的步骤流程
8.Reactor、Proactor模型,答了几种IO模型,以及Reactor和Proactor对应的IO模型,但是不是面试官想要的,面试官想问的Reactor哪三种实现,(事后也发现学过,但是忘记了,另外可能今天面的时候脑子也不好使,昨晚失眠了,一整天都是想呕的状态)
9.暂时想不起来了,最近几个月都没睡好,容易忘事….. 如果想起来了再更新进来吧
算法:力扣 困难题:接雨水 。 我使用栈的方式,提交发现确实有问题(牛客上不太熟悉看用例,也不好点击看全部,我怕切屏出去),然后也没给什么时间我调试了,面试官就说我这种实现方式有问题(这么说了我哪有心思调试),我说让我再看下,然后说这个你下去再看看吧, 事后再看了下,提交没过是有两个小问题,下面贴个截图吧
二面总结:
1)状态问题,这次二面提到的问题除了java框架类的,都是之前是有花时间学过也思考过的,但是就是忘记了或者说这次面试状态不是完全在线脑子迟钝(没休息好)
2)反思一下,之前学习的时候有些东西没有高度总结,当时学的时候确实影响深刻,但是过段时间特别想这种面试场景,可能因为前面答得不好心里的连锁反应,就会出现思考停滞、脑袋空白(主要是第一个问题就是java框架,可能自己心理素质也有关吧)
3)二面其实范围也不是很广,主要是比较深,网络相关的、redis、并发、设计模式这些个人感觉还是有一些沉淀的,然后还有一些案例设计、架构相关的都没问
4)自己经常用的java语言框架没准备,自以为像字节是go,java框架相关的应该不会问,要问也是一些架构设计相关或者设计题相关的
总结:有时候面试的时候,问到不会的或者顿时没有思路的,不要一时间脑子一片空白就内心慌了,可以多请教面试官能不能稍微指引一下,往往可以让你想起来,如果你真的之前有过深入全面的思考和总结的话,肯定能通过面试官的指引后说出远不仅只有标准答案的回答。另外要再多学会总结。 最近一直在准备,完全忽略了生活,或许缘分还没到、实力也还不够,长路漫漫,把心态和节奏缓下来, 再沉淀沉淀吧~
经过这次印象最深的问题:spring中bean的生命周期,去看了些相关八股文面试问题(这次面试前没看八股文),真不知道有些八股文相关面试题问出来有何意义,能体现出一个人的什么水平...
牛客网面经摘录
牛客网面经1(4年经验)
双非渣本后端三个月逆袭字节
作者:范特西Fantasy
链接:https://www.nowcoder.com/discuss/611627?channel=-1&source_id=profile_follow_post_nctrack
来源:牛客网
一面A部门
讲项目,串起来讲,可能遇到的问题,怎么解决,怎么实现,讲了发送客服消息
Spring里面的bean怎么回事
HashMap和ConcurrentHashMap,HashMap中的红黑树,两者rehash的区别
Mysql的一致性是什么,数据库redolog,undo log,MySQL的索引结构,为什么二级索引叶子节点不能直接存储行数据的指针,这样可以不回表,怎么考虑的?
redis里面的zset,跳表怎么实现,怎么增删,
redis是怎么rehash的
算法,二叉树转双向链表
二面A部门
二面A部门
自我介绍
再一次聊项目,功能,架构,角色,量级
Spring里面有哪些设计模式
SpringMVC和SpringBoot有什么区别
SpringBoot的自动配置是怎么实现的
刚刚你说了线程池,你线程池是用的什么,参数有哪些,为什么这么设置
线程池核心线程满了怎么办,里面的阻塞队列是干什么的
说说ThreadLocal是什么
CAP理论知道吗,为什么不能同时满足
Redis里面的数据结构有什么场景
Redis怎么实现锁(redis锁的所有坑都说了一遍)
分布式事务知道吗,有哪些方案(说了2PC,3PC,TCC,MQ)
算法题,树的直径
有什么要问我的
三面A部门
介绍项目
场景题,设计一个朋友圈,读QPS 1000w,写QPS 10w
算法题LFU
你有什么问题
一面B部门
介绍项目,细节
怎么做服务拆分,边界怎么划分的
分布式之后会遇到什么问题,CAP的各个情况介绍一下
dubbo调用过程是怎样的,PB知道吗
thrift了解过吗
zk介绍一下,有哪些节点类型,特点
怎么知道项目中接口的重要性,怎么做监控,你说的自动化测试是怎么做到的(这个问题回答完,他笑了。。。)
你所理解的SLA是什么,要达到什么等级
说说你理解的k8s
nginx的upstream是干什么的
nginx有哪些负载均衡策略
算法题:岛屿数量
你有什么问题要问我
二面B部门
介绍项目,细节
锁有哪些实现方式
分布式锁的实现方式
JVM的内存模型,垃圾回收算法
MySQL的事务介绍,ACID的实现原理是什么(想问MySQL的日志)
HashMap的原理,其他线程安全的Map
Redis的高可用,有哪些持久化方式
Redis的数据结构,线程模型
用过什么消息队列,有什么特点
怎么保证消息幂等消费
docker的网络模式
算法题:比较版本号
提问
三面B部门(交叉面)
介绍项目,细节
Linux的内存管理
浏览器打开一个网站的过程中会经历哪些网络处理,DNS的具体过程是啥
zk是什么分布式模型(想问的CAP定理),主从怎么做选举
zk只有一个主节点,写性能不高,zk怎么解决的
etcd或consul知道吗
多个服务中如何快速排查问题
Redis中的淘汰方式有哪些,Redis性能高的原因是啥
docker的实现原理
算法题:相交链表
四面B部门 (leader面)
介绍项目,细节
项目量级多大,QPS最高的接口是怎么做的
rpc怎么实现服务发现
zk中的watch机制是怎么实现的
分布式锁有哪些实现,MySQL,zk,Redis都说了一遍,并且分析了各自的优缺点,这个问题问的频率太高了
怎么提高数据库读写性能
k8s了解吗
servicemesh有做过吗
五面B部门(HR面)
离职原因
职业规划
期望薪资
基础知识
常用集合、数据结构(数据增删改查操作的原理具体实现、各参数的含义,以及如何组合使用)
Java的语法,OO的思想要熟悉,常用设计模式要知道场景
JVM内存模型,垃圾回收算法,垃圾收集器的区别,GC调优
线程模型
IO模型(包括操作系统底层IO模型和常见BIO、NIO、AIO、IO多路复用的原理)
Redis(数据结构的内部实现、淘汰原理策略、持久化、集群、扩容、数据同步、以及一些常见缓存问题的解决方案)
MySQL(索引原理,查询优化,三大日志)
消息队列(内部原理,常见消息问题解决方案)
分布式原理、算法、rpc原理(paxos、raft、zookeeper的原理)
分布式场景题(高可用,高性能相关)
其他知识
位运算
大数据量操作(在有限时间内完成、在有限空间内完成)
设计题(看一些常见的分布式ID、分布式计数服务等等)
算法
数组
链表
位运算
二叉树(dfs,bfs,相当重要,只要会了二叉树,回溯那些算法也会了)
设计题
LRU/LFU
排序
查找

牛客网面经2(2年经验)
腾讯,字节,虾皮,网易,微众面经分享
作者:淡ぅ的情
链接:https://www.nowcoder.com/discuss/663962?channel=-1&source_id=profile_follow_post_nctrack
来源:牛客网
我是清明节过后有离职的打算,工作经验将近2年,然后4月6号开始复习八股文。以下是最近一个月的面试经验,希望可以帮助到你。
腾讯1面(1.5小时)
自我介绍
项目
java hashmap源码
java 常用集合和部分源码
spring源码分析怎么解决三级缓存
springboot启动原理
java垃圾回收
jvm内存结构
tcp三次握手,四次挥手,超级详细,尤其是第四次挥手。各种状态,出现的问题,为啥必须第四次挥手,强行不要会干啥,线上问题对应tcp四次挥手哪些过程,怎么防止tcp攻击等等tcp和udp,详细介绍udp,报文大小多少,为啥。http 数据包大小,为啥。
http常用状态吗,502是啥
https加密的详细过程
操作系统调度算法和饥饿问题
操作系统虚拟内存,虚拟地址。
redis数据结构,底层数据结构
mysql索引相关的
linux常用命令
算法,寻找数组中重复的数字
反问
腾讯2面(1小时10分钟)
自我介绍
详细介绍项目,项目一些问题会深挖,然后问一些解决方案
tcp四次挥手深问
32位操作系统里进程可以分配内存大小,为什么。
epoll底层数据结构,原理
生产遇到问题及解决方案
操作系统虚拟内存,虚拟地址深问
算法,1面算法的变种
腾讯三面,我怀疑我没接到面试官电话,我当时在面别的,有个标记腾讯的电话回拨几次没人接,然后感谢信了,出师不利。
反问
虾皮1面(1.5小时现场)
1.自我介绍
2.redis底层数据结构,跳表,sds,渐进式哈希,redis超级详细
3.mysql索引,sql优化,线上慢sql排查解决
4.手撕堆排序
5.环状链表判断,找出交点,公式推导为啥
6.topk问题
7.epoll底层,水平,边缘
8.操作系统怎么进行端口映射
9.操作系统内存管理
10.linux命令查询topk问题,全局替换问题
11.二叉排序树寻找第k大
虾皮二面(1小时10分钟现场)
1.自我介绍
2.深挖项目
3.场景题,排行榜问题,各种很细的延伸,需要手写代码
4.一个大数组和小数组求差集,完全手写,输入输出,面试官说要拿回去敲代码运行那种。zijie反问
hr面
都一样,离职原因,期望薪资,现在薪资,手头offer等等。
微众1面(1.5小时)
自我介绍
问项目
java hashmap源码
juc并发包
spring用到哪些设计模式
服务注册中心怎么做的,原理
场景题,一个系统异步调用另一个系统,调用方调用第一个系统怎么做到同步,很深入问。
mysql索引
topk问题
linux命令 如top sed
线上内存泄露排查
反问
微众二面(1个小时)
自我介绍
全程问项目,场景问题
构架 很多不会
反问
微众三面(半个小时)
自我介绍
全程项目
线上问题排查
反问
反问
微众hr面
如上
网易hr(半小时)
意向,为啥来广州
网易1面(两个面试官并排坐问1小时10分钟)
1.自我介绍
2.问项目
3.spring bean得生命周期
4.springboot启动原理
5.mybatis源码
6.netty一些原理,是否线程安全,自己自定义解码器
7.springcloud dubbo部分原理
8.vue常用
9.redis你是怎么用的
10.mysql索引,sql优化
11.linux命令
反问
网易2面(两个面试官并排1个小时)
自我介绍
epoll底层原理,水平,边缘
mysql索引底层数据结构
红黑树和平衡树的区别
有点忘了,反正网易特别喜欢问框架,也会问前端。感觉就是全栈工程师。问的都是框架问题
反问
网易hr
如上
字节1面(1小时)
自我介绍
问项目
http常用状态码 502?
网络拥塞现象排查,为啥网络传递越来越快(慢开始算法)
mysql事务,索引,锁等等
redis数据结构和底层原理
raft原理,一致性hash算法
dubbo负载均衡,根据场景你选用哪种,为什么
你谈谈你对zk的理解,redis分布式锁有啥问题
springcloud,注册中心原理,配置中心原理,dubbo服务发现,熔断限流。
算法.合并区间
字节2面(1小时)
自我介绍
深挖项目
算法.二叉树排序树求第k大,自己构造二叉排序树,怎么不使用全局变量优化这个算法
反问
字节三面
自我介绍
深挖项目
反问
字节hr面,如上
总结,腾讯特别喜欢操作系统和网络,字节和虾皮喜欢算法,网易喜欢问框架。面试完没有整理,很多都忘了,把自己记得写了下来。
牛客网面经3
腾讯后台开发,社招六面面经(C++)
刷题:leetcode精刷100题。《剑指offer》,这里也要推荐下,面试的手写算法考察大概有50%的题型出自本书。考察的手写算法题基本上来自 leetcode(简单和中等题型) 和《剑指offer》。
基本的排序算法一定要掌握,比如冒泡、选择、插入、快排、归并、堆排、桶排序、基数排序。这些排序的时间复杂度和空间复杂度以及区别、使用场景一定要了然于胸,快排、归并、堆排要能够迅速手写出来
算法方面还可以参考左神的《直通BAT算法精讲》系列视频。除了基本的数据结构之外,红黑树,平衡树考察的也比较多,这里也要重点关注下。
操作系统这一块,重点关注进程管理、调度、进程间通信、线程同步、内存管理、虚拟内存等等。复习的方法是先总结网上面经提到的考点,然后结合书本分析。这一块我主要看了《深入理解Linux内核》,《Linux环境编程:从应用到内核》两本书。这里推荐下《Linux环境编程:从应用到内核》这本书,无论从实战还是原理角度来讲,都讲的非常好。
计算机网络考察的主要是原理性知识,这里重点关注TCP协议。这一块的复习工作,我主要参考了《计算机网络 谢希仁版》的TCP那一章节,腾讯的TCP知识考察基本上都在这一章,考点包括TCP的三次握手、四次挥手、拥塞控制、nagle算法,karn算法等等。这一块相对来说,只要复习到位,难度不大。
腾讯的面试的流程持续一个多月,如下:
第一轮电话面试,技术面。
第二轮电话面试,技术面。
第三轮和第四轮现场笔试+面试,技术面(原定9月31号,国庆放假推迟一周)。
第五轮现场复试,技术面。
第六轮HR面。
offer call。
第一面流程:
计算机网络、操作系统。内容包括TCP拥塞控制算法、TCP和UDP区别、进程和线程区别等等。
第二面流程:
Q2. 网络字节序是大端序还是小端序?
A:大端序。
Q3. Linux中如何创建进程以及创建进程后如何区分子进程?
A:使用fork()调用创建子进程,fork()调用返回两个值,大于0的表示父进程,等于0的表示子进程。
Q4. fork创建的子进程继承了父进程哪些内容
A:子进程继承了父进程的地址空间,打开的文件描述符等。
Q5. fork创建的子进程继承了父进程打开的文件描述符,如何让这种继承不发生
A:可以在打开文件的时候,设置FD_CLOSEXEC标志位,如果文件描述符中这个标志位置位,那么调用exec时会自动关闭对应的文件。
Q14. 快速排序的时间复杂度
A:快速排序平均时间复杂度位nlogn,最差O(n^2)
Q15. nLogn是排序最好的时间复杂度吗?
A:不是,还有O(n)的算法,比如说基数排序。
Q16. 基数排序的原理以及应用
A:基数排序根据一个数的高低位进行排序。应用不知道,缺点是对负数的处理不太好。
Q17. 介绍负载均衡的应用
A:不知道。
Q18. http协议有用过吗?
A:这个没用过。
Q19. protobuf协议
A:我们公司之前使用的是json协议,没有用过protobuf协议。
Q21. redis
A:这个是自己学习使用的,生产环境没用过(这里说了下,我用它干嘛的,使用python的flask web框架基于redis的list结构开发一个网络聊天程序)
Q22. 解释线程安全和可重入函数
Q23. top的命令***和buffer区别
A:这个平常没有关注过。(buffer是块设备的读写缓冲区,比如磁盘,***是文件系统的缓存,常用于文件)
Q24. 常见Linux命令是否用过,比如strace和netstat
A:这个有用过,strace用来跟踪程序的执行,top查看内存,以及tcpdump等进行抓包等等。
Q26. 智力题,100本书,两个人轮流拿,每次拿1~5本,你先拿,有没有啥策略可以保证你可以拿到最后一本?
(此题解法可以是先手拿4本,后续双方每次拿6的倍数,这样可以保证最终可以拿到最后一本)。
第三面流程:
给了一张试卷,1.5小时完成。如果难度分成5个等级,感觉介于2和3之间。试卷内容保密。总之,考察比较基础也比较全面,C++,操作系统,计算机网络,算法和数据结构。
3点半,两个面试官。对着简历介绍项目,细节,技术难点,架构设计
5. 设计一个内存池。
6. 设计一个定时器
10. TCP粘包怎么解决。
11. 设计线程池。
14. 画出四次挥手原理图。
17. accept是在三次握手哪一次。
第四面面试流程:
大概是总监。
第二题,N个M长度数组求交集,求最优解并给出时间复杂度和空间复杂度。我给出的方案是归并、去重、全排序。然后问了下为啥用归并排序,于是介绍快排、归并、堆排各自优缺点和使用场景。然后问有没有更好的解法。想了下,给出了优化方案,仍然是归并,去重,然后hash。然后过。
第三题,c++手写单例模式,《剑指offer》第二题。
给定一个日志文件,每行包括日期,IP地址,错误码。然后让我使用shell搜索指定日期,指定IP,指定错误的日志出现次数。
简单题,grep -rns "date + IP + error" | wc -l
应该是考察我awk的使用。这里提醒各位同学,自称会shell开发一定要掌握awk和sed的使用。基本上,面试官看到自称会shell必考。
第五面流程:
1. 介绍前公司产品的功能、市场竞争力、自己负责的部分、产品的软件架构。
4. 概率题,两个红球一个白球,三个盒子。问第二个盒子至少一个红球的概率。
5. 编程题,字符串去空格。
6. 进程、线程区别。为什么有了多线程还是用多进程。
7. 平时如何定位问题,core dump怎么产生的。
9. 算法题:给定电话号码加区号,如何快速查找对应地区。
14. 阅读源码有啥好处?对以前的项目有没有啥改进之处?
第六面(HR面)
距离复试三天时间。中午电话。
1. 为啥学些德语。
2. 第一份工作学习到啥。
3. 对腾讯怎么看。
4. 期望薪资以及依据。
5. 当前薪资、福利。
6. 以前是通信的,对互联网怎么看。
7. 部门业务量很多,可能需要加班,你怎么看。
8. 有啥问题想问的。
两天后,给了oc。腾讯的面试流程大体这样,技术面考察的都是基础,要有深度,不能停留在表面。自己前前后后准备了四个月,从第一次的惨败到后期的从容面对,一步步走下来,收获满满,最终得到想要的结果。
牛客网面经4(2年)
作者:郁南
链接:https://www.nowcoder.com/discuss/702869?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
B站的后端开发岗社招一面面经和答案分析分享
郁南
编辑于 2021-08-11 14:37:50APP内打开赞 8 | 收藏 50 | 回复1 | 浏览4132B站的后端开发岗社招一面面经和答案分析分享APP内打开 8 50 1 分享
文写这篇主要是想复盘一下我的两次面试经历,一个是B站的后端开发岗,另一个是百度的搜索研发。文章涵盖了MySQL、Golang、 计算机网络、Elasticsearch、 分布式、搜索的一些知识。
写在前面
1.你之前是负责搜索的,那我想听一下你们搜索系统的大致流程
说实在还挺惊讶面试官会问这个的,因为对方是一个后端工程师,所以就没讲多细致,答的很general,大体来说就是,query分析->粗排召回->精排算特征-> learning to rank计算score ->返回结果,每个再展开来说一些即可。面试官问这个相当于在问项目,确定简历的真实性,所以这个没啥参考性。
2.MySQL的事务隔离级别有哪些?
总共是四大隔离级别,理解以后用自己的话答就好了
面试官还是比较满意这个答案的,但接下来面试官问:
3.以上事务隔离是如何实现的?
老实回答,这题我不会,面试官提示MVCC,我还是不会hhh。回去翻了一些资料,在这里补充一下答案。所谓的MVCC就是MultipleVersion Concurrency Control,多版本并发控制,从名字上也可以看出来,它是使用版本号来对数据进行并发控制的。实际上,在数据表的每一列,都存储两个隐藏列,一个是trx_id,代表事务的ID,另一个是roll_pointer,指向其上一个版本的记录,如此组成一个记录的版本链,接下来就可以讲ReadView了,它存储着一种用来记录当前活跃状态的读写事务,用于判定该transaction可见到的数据版本。
4.MySQL索引的原理是什么?
B+树,本质上它是将瘦长的平衡二叉树,改造成一个矮扁的平衡多叉树从而减少IO查询次数,平均查询复杂度仍能保证O(logN),另外与B树不同的是,除了叶子结点外,其他结点均不存储数据,另外叶子结点之间,用链表方式相连以加速查询。当然视面试官的反应,可以再补充B+树的插入和删除操作。
5.MySQL建立索引时,应该注意什么?
这个按照自己的经验来回答了,三点:1.对区分度高的列做索引, 对于那种只有两三个值的做索引并没有多大意义。2.建立联合索引时要满足最左匹配原则,例如SELECT * FROM TABLE WHERE A=1 AND B=2 AND C=3,此时需要对ABC建联合索引, 对ABC单独建三个索引是没用的。面试官又问,那我对BAC建联合索引就命中不了索引了吗?我说是的,被面试官怼了一下,其实MySQL在很久以前就在查询优化器里加入了这个feature,是可以命中的。3.只对需要作为查询条件的列建索引,否则会拖慢插入速度。
6.MySQL存储引擎由哪些?他们有什么区别?应用场景是怎样的
也是一道经典MySQL题了,主要分为Innodb和MyISAM,最主要的区别在于InnoDB采用的簇集索引,MyISAM采用的是非簇集索引。
对于非簇集索引来说,叶子结点存放的值实际上是data域的地址,data和 索引是完全分离的。
7.用户从输入URL到看到浏览器展示结果,经过了哪些过程?越详细越好。
8.redis的数据类型有哪些?在哪些场景使用?
string, set, list, hash dict, zset
string就是经常用的key value键值对;
hash dict可以表示一个对象,是一个field和value的映射表;
set就是集合,用hash来实现的;
list本质上是个双端队列, 可以实现从左边add也可以从右边add
zset是有序集合, 用跳表来实现,可以用来实现实时排行榜。
9.redis设置过期时间的原理是怎样的?
这个我没有看过,但是我猜了两种策略,给猜对了:1.惰性删除,像限流器那样,只有在get的时候去检查它是否expire,如果过期,就删除。2.定时删除。 具体的我没想对,回去看了一下,官方给出的答案是这样的:
Specifically this is what Redis does 10 times per second:
Test 20 random keys from the set of keys with an associated expire.
Delete all the keys found expired.
If more than 25% of keys were expired, start again from step 1.
也就是说,每秒做10次这样的行为: 从所有设置过期时间的key中, 随机选择20个key,删除所有过期的key, 如果25%的key都过期了,就回到步骤1再做一次。
10.你刚才提到了限流器,如何实现一个限流器?
限流器的原理就是令牌桶,按照一定的时间往桶里加入Token,如果桶已经满了丢弃令牌。每个新请求就消耗一个token, 如果token没了就拒绝服务请求。新请求来临时,会请求从桶中拿走一个Token,如果没有Token可拿了就阻塞或者拒绝服务请求,它的所有计算本质上都是惰性计算。
11.Goroutine为什么这么轻?
简单来说,因为它是发生在操作系统的用户态的,不需要进入内核态进行系统调用,操作系统的上下文切换会带来很大的开销,切goroutine和线程一样,共享堆,不共享栈。
Golang的垃圾回收是怎么做的?
很早之前看过,刚好被问到了就答的比较顺利。三色并发标记,基本思想是把内存中的所有对象分为黑白灰三类,一开始所有对象都是白色对象,然后把所有可达对象标记为灰色,再从所有灰色对象出发,将所有触及到的对象标记为灰色,自身灰色标记为黑色对象,如此循环往复,直到没有灰色对象为止,由于每次标记剩下的都是不可达的白色对象,所以直接将白色对象删除即可。
牛客网面经5(2年C++)
作者:darksidewow
链接:https://www.nowcoder.com/discuss/702115?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
百度智能云账号和消息部门
一面:
1、项目
2、讲一下AOP吧
3、动态代理和静态代理有什么区别
4、TCP和IP报文是否会分片,分别在什么情况下会分片,TCP分包之后是否还会进行ip分片
5、写一个斐波那契数列
6、讲一下Linux的内存结构,我说只会JVM的,他让我说一下。
二面:
1、项目讲一下
2、排序算法,复杂度,比较。快排的空间复杂度是logn。
3、讲一下OSI七层模型,每层的作用,wifi属于哪一层。
4、线程间的同步用什么方式,使用hashmap时重写哪两个方法,为什么要重写,什么场景下重写。
5、平时用过什么数据结构,list用哪些有啥区别。
6、Spring中的ioc和aop,ioc的注解有哪些,autowired和resource有什么区别,作用域有哪些,autowired如何配置两个类中的一个。
7、写一个单例模式。
8、Java会有内存泄漏吗,三个区分别什么情况下会产生内存泄漏。
三面:
1、主要了解哪些技术。
2、分布式系统怎么设计。
3、最终一致性是什么,举一下强一致性和最终一致性的例子。
4、分布式事务的消息id怎么确认顺序。
5、zk的性能瓶颈怎么克服。
6、跨机房的网络延迟怎么解决。
7、网络这块熟么,说一下socket编程吧。说了一下java的socket。
8、网络编程的NIO和BIO区别,阻塞指的是什么意思呢。
9、socket客户端和服务端的连接过程和通信过程说一下。
10、操作系统熟么,shell和命令熟么。
11、算法熟么。
12、系统怎么设计,设计模式怎么用
13、系统优化怎么做,cpu,IO,内存分别怎么排查问题和调优
牛客网面经6(2年)
作者:HuperMaster
链接:https://www.nowcoder.com/discuss/701984?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
有赞、字节等后台开发岗社招面筋分享
HuperMaster
编辑于 2021-08-09 19:58:06APP内打开赞 3 | 收藏 63 | 回复4 | 浏览6519有赞、字节等后台开发岗社招面筋分享APP内打开 3 63 4 分享
有赞:
一面
· hashMap原理,put和resize过程
· 线程池有哪些类型,
· concurrentHashMap分段锁原理,java8和java7实现的区别
· B-树和B+树区别,数据库索引原理,组合索引怎么使用?最左匹配的原理
· spring生命周期,几种scope区别,aop实现有哪几种实现,接口代理和类代理会有什么区别
二面
· 项目介绍
· 斐波那契数列非递归实现
· 短URL实现
三面
· HR+主管
· 你现在做的事情,为什么要离职?反正对你性格生活薪资全面了解
字节:
一面
· 自我介绍,做的项目价值,架构设计,给你一个集群你会怎么分布,考虑哪些因素,容灾、负载均衡
· 让你来设计咸鱼,你会怎么设计?模型设计
· linux常用指令
二面
· 算法在线编程
· 项目,主要做了什么,项目中碰到的问题有哪些,都市怎么解决?你觉得哪个项目是最有挑战的
· java多线程,线程池的选型,为什么要选这个,底层实现原理
三面
· 你最熟悉的项目,做了什么,为什么这么做,怎么体现你项目的价值
· 让你来推广广告,你会怎么设计?
· java基础问了些,JVM内存模型 G1和CMS垃圾回收器
· 如何中断线程,await和sleep区别
· 设计一个秒杀系统
· spring生命周期,几种scope区别
四面
· 跟上面差不多
五面
· 主管面,主要问项目,然后说下他们在做什么
六面HR
· 期望薪资,为什么要离职,现在的级别,会考北京的原因
网易:
一面
· RPC原理,netty原理
· hashMap原理
· redis缓存回收机制,准备同步,哨兵机制
· 要统计10分钟内订单的亏损,你会怎么设计(strom窗口模式)
· 项目:你做了什么,为什么要这么做,用了什么技术要解决什么问题
二面
· 分布式缓存redis原理,zookeeper锁是如何实现的
· 分布式缓存读写不一致问题
· java线程你是怎么使用的
· 数据库是如何调优的
· git rebase命令发生了什么
· 讨论项目
三面HR
· 薪资,为什么要离开,级别
华为
一面
· 结构数据库和非结构数据库区别,你了解的非结构数据库有哪些
· 频繁的增删数据量某个表,数据库最终数据只有几万或者更少,为什么查询会变慢
· 数据如果出现了阻塞,你是怎么排查的,top和jstack命令用过没,jstack命令的nid是什么意思,怎么查看java某个进程的线程
· 大数据算法聚类算法有哪些
· 写一个算法判断某个数是2的n次方
· 说你最熟悉的项目
二面HR
· 薪资级别,你是怎么抗压的,平时喜欢做什么,对加班什么看法
三面业务主管
· 你想做什么,会给你介绍他们部门做的东西
· 你自己做的项目,怎么设计的
牛客网面经7(1年经验)
作者:你的小王子啊
链接:https://www.nowcoder.com/discuss/699189?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
蚂蚁金服资深工程师面试经验分享
你的小王子啊
编辑于 2021-08-06 11:43:12APP内打开赞 4 | 收藏 119 | 回复5 | 浏览6039
蚂蚁Java一面
1.二叉搜索树和平衡二叉树有什么关系,强平衡二叉树(AVL树)和弱平衡二叉树(红黑树)有什么区别
2. B树和B+树的区别,为什么MySQL要使用B+树
3. HashMap如何解决Hash冲突
通过引入单向链表来解决Hash冲突。当出现Hash冲突时,比较新老key值是否相等,如果相等,新值覆盖旧值。如果不相等,新值会存入新的Node结点,指向老节点,形成
链式结构,即链表。当Hash冲突发生频繁的时候,会导致链表长度过长,以致检索效率低,所以JDK1.8之后引入了红黑树,当链表长度大于8时,链表会转换成红黑书,以此提高查询性能。
4. epoll和poll的区别,及其应用场景
select和epoll都是I/O多路复用的方式,但是select是通过不断轮询监听socket实现,epoll是当socket有变化时通过回掉的方式主动告知用户进程实现
参考文章:https://www.cnblogs.com/hsmwlyl/p/10652503.html
5.简述线程池原理,FixedThreadPool用的阻塞队列是什么?
6. sychronized和ReentrantLock的区别
(1)ReentrantLock显示获得、释放锁,synchronized隐式获得释放锁
(2)ReentrantLock可响应中断、可轮回,synchronized是不可以响应中断的,为处理锁的不可用性提供了更高的灵活性
(3)ReentrantLock是API级别的,synchronized是JVM级别的
(4)ReentrantLock可以实现公平锁
(5)ReentrantLock通过Condition可以绑定多个条件
7. sychronized的自旋锁、偏向锁、轻量级锁、重量级锁,分别介绍和联系
8. HTTP有哪些问题,加密算法有哪些,针对不同加密方式可能产生的问题,及其HTTPS是如何保证安全传输的
HTTP的不足:
通信使用明文,内容可能会被窃听;
不验证通信方的身份,因此有可能遭遇伪装;
无法证明报文的完整性,有可能已遭篡改;
常用加密算法:MD5算法、DES算法、AES算法、RSA算法
蚂蚁Java二面
1.设计模式有哪些大类,及熟悉其中哪些设计模式
创建型模式、结构型模式、行为型模式
2. volatile关键字,他是如何保证可见性,有序性
3. Java的内存结构,堆分为哪几部分,默认年龄多大进入老年代
Java的内存结构:程序计数器、虚拟机栈、本地方法栈、堆、方法区。
Java虚拟机根据对象存活的周期不同,把堆内存划分为几块,一般分为新生代、老年代和永久代。默认的设置下,当对象的年龄达到15岁的时候,也就是躲过15次Gc的时候,他就会转移到老年代中去躲过15次GC之后进入老年代。
4. ConcurrentHashMap如何保证线程安全,jdk1.8有什么变化
JDK1.7:使用了分段锁机制实现ConcurrentHashMap,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;
而每个Segment元素,即每个分段则类似于一个Hashtable;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作,不过其最大并发度受Segment的个数限制。
JDK1.8:底层采用数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现
5.为什么ConcurrentHashMap底层为什么要红黑树
因为发生hash冲突的时候,会在链表上新增节点,但是链表过长的话会影响检索效率,引入红黑书可以提高插入和查询的效率。
6.如何做的MySQL优化
MySQL的优化有多种方式,我们可以从以下几个方面入手:
存储引擎的选择、字段类型的选择、索引的选择、分区分表、主从复制、读写分离、SQL优化。详细优化请查看参考文章
7.讲一下oom以及遇到这种情况怎么处理的,是否使用过日志分析工具
蚂蚁Java三面
1.项目介绍
2.你们怎么保证Redis缓存和数据库的数据一致性?
可以通过双删延时策略来保证他们的一致性。
3. Redis缓存雪崩?击穿?穿透?
缓存雪崩:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
缓存击穿:key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存穿透:key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
4.你熟悉哪些消息中间件,有做过性能比较?
差不多整个过程就是这样啦,希望对大家有所帮助吧。
牛客网面经8(2年)
作者:@聒噪
链接:https://www.nowcoder.com/discuss/695133?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
【社招】商业化技术后端一二三面(已凉)
@聒噪#字节面试#
编辑于 2021-08-10 11:13:00APP内打开赞 4 | 收藏 62 | 回复8 | 浏览4555【社招】商业化技术后端一二三面(已凉)APP内打开 4 62 8 分享
双非本科两年经验
7月21 一面【66分钟】
自我介绍
项目介绍
项目难点。以及解决方案
Redis 在项目中是用来做什么的
数据库的数据和Redis中的数据是如何保持一致的
删除Redis数据的时候没有删除成功怎么办
数据库 左连接、右连接、内连接、外连接区别
项目数据量多少
项目数据存储时怎么优化的
分库分表的话查一条数据怎么查?(通过分片键和分片规则,找到这条记录的存储位置,再查找)
SQL题(有一张考试分数记录表exam,包含字段(id,student,subject,score;)选出每个student的最高score记录,需要包含所有字段)
JVM的堆是如何分区的?
Gc垃圾回收算法
哪些数据是不可达的
Synchronized 1.8后做了那些优化
轻量级锁
数据库的索引大多用的是B+树,为什么很少用B树
leetCode 2 两数相加
反问
7月23 二面【55分钟】
自我介绍
项目中用到的技术栈的介绍
SpringCloud 组件介绍,及微服务之间是如何调用的
Java类加载器有哪些种类,每种都用来加载什么
双亲委派,String 类是由那个类加载器加载的
volatile 关键字原理
Java线程池的参数有哪些
线程池运作过程是怎样的,这里面的队列有哪些,无界对列当任务很多的时候或发生什么?线程池默认的队列是什么
Spring对象的SCOP 知道吗
Spring中常用的设计模式举4例子
介绍下动态代理
事务的ACID
介绍下Mysql的隔离级别,可重复读回出现什么问题(幻读)什么是幻读,怎么避免幻读
Redis的两种持久化模式
算法LRU
7月30 三面【60分钟】
自我介绍
项目介绍
微服务的优缺点
智力题 从9个人如何用一枚六面的筛子选出两个人
Seata的分布式事务介绍
如何设计一个高可靠的分布式锁
给定一个二维网格和一个单词,找出该单词是否存在于网格中。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
board =
[
['A','B','C','E'],
['S','F','C','S'],
['A','D','E','E']
]
给定 word = "ABCCED", 返回 true
给定 word = "SEE", 返回 true
给定 word = "ABCB", 返回 false
反问
三面面通过
8.3号hr面
8.10号收到感谢信已凉
牛客网面经9(3年)
作者:小洪1617
链接:https://www.nowcoder.com/discuss/673974?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
度小满金融Java一二面凉经
小洪1617
编辑于 2021-06-21 10:11:05APP内打开赞 7 | 收藏 70 | 回复5 | 浏览8484度小满金融Java一二面凉经APP内打开 7 70 5 分享
二面完了就没有消息了,估计是凉透了,把面经发出来,希望能帮助到大家~
一面
1.如何设计Restful接口
2.get和post的区别
3.常见的HTTP请求头有哪些,User-Agent的作用
4.JDK1.8之后的新特性(不包括1.8)
5.说一下MySQL的事务隔离级别,RC和RR分别解决了什么问题
6.聚簇索引和非聚簇索引的区别
7.索引失效的原因可能是
8.Redis有哪些数据结构,常用场景
9.Redis除了做缓存,还能做什么
10.JVM内存模型,1.7和1.8的区别
11.常见的GC算法,年轻代和老年代一般用哪种算法
12.G1相比CMS的优势
13.JUC包,CopyOnWriteArrayList是什么
14.ConcurrentHashMap,1.7和1.8的区别
15.synchronized是可重入锁吗(因为1.8的时候我提到了synchronized的锁升级)
16.给定一个字符串,形式是"00000011111",找到第一个1的位置
二面
1.RPC和HTTP的区别
2.Java的Map有哪些实现类,分别简要介绍一下
3.说一下HashMap的原理,为什么用链地址去解决冲突,为什么用红黑树
4.kafka如何保证消息不丢失
5.MySQL的事务隔离机制,如何实现的
6.什么是事务,事务的四大特性,一致性是如何实现的
7.MVCC是什么,如何实现的
8.说一下常见的设计模式,实现一下单例模式
9.单例模式有哪几种,二者有什么区别,什么时候用哪种
10.TopK算法
11.优先队列和堆的区别
总结:我简历上没有写消息队列跟RPC,没想到还是问了,所以这两题不会,其他都答得挺好的。面试官最后给我的评价是知识深度可以,但广度还需要加强。所以大家如果要准备该公司的Java面试的话,还是要去看一下RPC跟Kafka相关的知识,至少也要提前去看点面经。
牛客网面经8(3年)
作者:小洪1617
链接:https://www.nowcoder.com/discuss/673976?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
字节抖音Java一二面凉经 烫 内部员工回复
小洪1617
编辑于 2021-06-21 10:11:52APP内打开赞 34 | 收藏 242 | 回复33 | 浏览12461字节抖音Java一二面凉经 烫 内部员工回复APP内打开 34 242 33 分享
内部员工参与评论 (共1人 查看全部 )
写在前面:一面问得过于简单,二面过于困难。整体的体验不太好。。
一面
1.Java如何实现线程安全(synchronized,ReentrantLock,AtomicInteger,ThreadLocal,CAS)
2.CAS如何解决ABA问题(版本号)
3.AtomicInteger的原理(UnSafe类,底层是一句CPU指令,避免了并发问题)
4.可重入锁是什么,非可重入锁又是什么(略
5.代码,实现生产者和消费者,一个长度100的buffer,10个生产者线程,10个消费者线程
(我用了ReentrantLock跟Condition,结果忘记了锁的包路径是啥了,我写成了java.util.concurrent.,后来才知道是java.util.concurrent.locks.。。。)
6.对着代码提问,判定条件的while能不能换成if,为什么?为什么用signalAll,可不可以换成signal,二者有什么区别?
7.Spring,AOP是什么,IOC是什么
8.二叉树的概念?红黑树又是什么,红黑树和其他平衡树的区别在哪
9.TCP三次握手的过程,重发报文的过程。
10.TCP和UDP的区别
11.说一下哪个项目觉得最有挑战,有几个模块,介绍一下
12.代码,LeetCode76
二面
1.MySQL的事务特性,事务隔离级别,分别解决了什么问题
2.间隙锁是什么,具体什么时候会加锁(具体什么时候加锁,这里要把所有情况都说清楚。。
3.SQLite如何加锁
4.Java里的锁,有哪几种(synchronized和Reentrantlock)
5.ReentrantLock有哪些特性(可重入,公平锁),可重入是如何实现的(有一个引用数,非可重入只有01值)
6.当某个线程获取ReentrantLock失败时,是否会从内核态切换回用户态?ReentrantLock如何存储阻塞的线程的?(AQS,不断轮询前一个结点是否状态发生了变化)所以什么是自旋锁?
7.JVM,说一下最熟悉的GC(我说了CMS,讲了并行回收,浮动垃圾,最短STW等等),然后追问我CMS的整个回收流程,标记,清理等等,年轻代怎么回收等等。(被问倒了。
7.Redis的持久化如何做到的?(RDB+AOF)
8.RDB具体是如何实现的,RDB生成快照的时候,Redis会阻塞掉吗?(使用BgSave,fork一个子进程去并行生成快照,不会阻塞)
9.既然生成快照的中途依然可以执行Redis,那么从节点获取到快照是不完整的,如何同步?(主从同步,先建立连接,然后命令传播,两个结点中的buffer队列里存储一个offset,差值就是需要同步的值)
10.设计题,设计一个扫码登陆(不会)那换成设计微信红包功能(MySQL的字段,Redis缓存一致性,发红包如何add字段,抢红包如何修改字段,通过一个唯一的版本号去保证CAS的ABA得到解决。但说了很久,面试官依然认为思路混乱)
11.算法题,n*n的矩阵,只能向右或向下移动,从最左上方移动到最右下方,把所有的路径输出(回溯,但剪枝忘了。前面的也答得不好,差不多就溜溜球了,也没有继续挣扎了。。)
碎碎念
一面的面试官爱理不理的,感觉就不是很想招人。但最后出了一题hard,也做出来了,感觉应该还是能过的,确实也通过了。
但二面真的太难了,每一个问题都会一直细问,追问。其实ReentrantLock,还有MySQL的锁,Redis的持久化过程,我都有认真去复习的,但真的追问得太细了。。其实当时他第一题问“MySQL具体什么时候加锁”,我就挺懵的了。因为这个题我确实研究过很久,要综合考虑隔离级别,是否用了主键索引,二级索引,是否存在回表等等的。所以当时我也不知道怎么回答,然后冷静下来就定位到了间隙锁上也就是肯定为RR级别,接着把大概的select,insert,delete等等的都说了,但后面还要继续说更细节的情况。我也不知道是我对题目的理解有问题,还是面试官想要的答案跟我不一致。反正挫败感很强,因为我记得当时看“这条SQL语句加了什么锁”,真的看了很久,而且自己也动手去测试了,结果还是没能满足面试官。。
面试官看我对锁的理解“不够深入”,于是转向了Java里的锁。问完ReentrantLock的特性,又问什么是可重入锁,说完又问具体是怎么实现的。直到这里我还是完全OK的,但后面的“线程在用户态和内核态的切换”我就完全不懂了,面试官诱导了一下ReentrantLock如何实现,我大概说了一下AQS跟CLH锁,感觉又被挖坑了,跟前面说的“可能答案”自相矛盾。。
接着的Redis持久化,也追问得很厉害,从持久化问到主从同步。。中间追问的时候描述得也比较“模糊”,后来在提示下才知道是问主从同步了,然后把整个过程都说了一下。。
接着的设计题,没接触过。。说了很多,感觉还是不行。
算法题基本上已经是“垃圾时间”啦,确实也出了一题很简单的题,大概做出来之后就算了。面试官问我如何优化,我也深知已经没戏,就直接放弃说不会了。然后面试就到这里。
总的来说,其实二面的面试官挺温柔的,但问的题对于我来说太难了。。所以,第二天收到HR的感谢信。over。
牛客网面经10(4年)
作者:Jessin
链接:https://www.nowcoder.com/discuss/680574?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
小红书java社招一面面经
Jessin
编辑于 2021-07-09 10:53:16APP内打开赞 6 | 收藏 93 | 回复7 | 浏览5686小红书java社招一面面经APP内打开 6 93 7 分享
hashmap的底层数据结构,put的过程
hashmap是否是线程安全的,多线程下会有什么问题?concurrentHashMap底层是如何实现线程安全的。
synchronized锁的升级过程。
数据库是否用了索引?用explain无法看出索引用了哪一部分?
https://blog.csdn.net/houmenghu/article/details/109580196
遇到非等值判断时匹配停止
1
2
3
4
5
a = ? and b = ? and c= ?
a = ? and b = ? and c > ?
a = ? and b > ? and c > ?, 只用到索引的一部分(a,b),因为b把数据阻断了,b不是定植时,c时无序的,无法使用(a,b,c)索引。
show global variables like 'optimizer_switch'\G
5.6版本后,可以开启索引下推。虽然有非等值条件,导致索引不能全部使用,但是可以利用索引条件,里面有的字段进行过滤,过滤后再回表读取真正的数据(extra=using index condition),而不是只根据部分索引查出该索引符合条件的数据(回表数据太多,回表一般是随机io,减少回表次数),然后再server层进行过滤,这样效率会很低(extra=using where):
extra=using index是覆盖索引
type=index,表示使用索引排序
http://fivezh.github.io/2020/01/19/mysql-icp/?utm_source=tuicool&utm_medium=referral
spring循环引用的问题,A->B->A问题
spring对于单例模式,用了三级缓存
getBean(A)时,先实例化A,然后曝光到singletonFactories中,允许循环依赖。初始化结束后,再从提前曝光缓存earlySingletonObjects以及singletonFactories移除,挪到singletonOjbects单例缓存中。
getBean(B)依赖A,先在singletonObjects 中查找,如果有直接返回。如果不存在,在earlySingletonObjects中查找,这个是提前曝光,还未初始化的单例。如果不存在,在singletonFactories中查找,找到后放回earlySingletonObjects。这个时候A还没初始化。
举个不用回表的例子
覆盖索引
1
2
index (name, age)
select name,age from t where namg = "xiaoming";
主键用uuid会有什么问题?
聚蔟索引和非聚蔟索引的区别,是否分别对应主键索引、辅助索引?是的
https://www.jianshu.com/p/643850f684db
mysql索引,高度一般是3-4层,innodb的页大小是16kB,叶子节点是双向循环链表?一个b+树存储行数最多为2000w
https://zhuanlan.zhihu.com/p/86137284
实现LRUCache,这里可以考虑用map,节点是node,node之间通过前后指针关联,双向链表
https://leetcode-cn.com/problems/lru-cache/
存在个问题,一批新数据会把访问很久的数据给挤出去,这里如何解决这个问题?
https://juejin.cn/post/6844904049263771662
https://segmentfault.com/a/1190000038714624
jvm垃圾回收是如何做的?
jvm运行时有哪些数据区
哈希冲突如何解决
b+树叶子节点存的是指针吗?存的是数据
可重复读的情况下,select count(*) from t where a >= 0 and a <= 10在另一个事务执行前后效果如何?可重复读下,对于更新语句,会加锁。只不过是通过mvcc来实现可重复读,依然会出现幻读的现象,需要改为当前读
CMS和G1均使用三色标记法进行标记,一开始是白色对象。
黑色对象,自己和成员对象均已标记存活。
灰色对象,中间状态,自己存活,但是成员对象未标记(白色)
白色对象,未标记或者没有访问到(可以回收)
跨代引用
新生代引用老年代如何回收,直接扫描,因为新生代朝生暮死。
老年代引用新生代,回收新生代时minorgc,使用card table,牺牲空间换时间,减少扫描整个老年代的时间,因为老年代的存活时间是比较长的。https://www.jianshu.com/p/f1ff4ab0fed7,g1引入了remember set
write ahead log
https://martinfowler.com/articles/patterns-of-distributed-systems/wal.html
延迟关联,解决深分页问题
http://qidawu.github.io/2019/11/26/mysql-deferred-join/
====================
网易Java开发社招一面
作者:Arealy仁辰
链接:https://www.nowcoder.com/discuss/683560?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
JVM内存模型;
Java锁机制、锁升级;
TCP三次握手、四次挥手;
路由输入URL到页面显示过程中发生了什么;
NIO、BIO、AIO的区别和使用场景(HTTP请求默认是NIO还是BIO);
TCP和UDP的区别,以及保证通信的机制有哪些(滑动窗口、拥塞控制、慢启动、快重启、快恢复等);
进程间通信的方式有哪些;
了解什么设计模式吗,在工作中什么场景中会用到?
作者:Arealy仁辰
链接:https://www.nowcoder.com/discuss/684765?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
====================
阿里Java开发社招一面(1年,P5+)
Arealy仁辰 #阿里巴巴社招#
编辑于 2021-08-02 17:15:46APP内打开赞 10 | 收藏 77 | 回复19 | 浏览8065
一年经验,Java开发
时间:2021年7月15日(1小时53分钟,电话)
自我介绍;
项目延申;(延展的非常非常非常深);
new一个对象,从底层来说会发生什么;
new一个HashMap,for循环put进入10000个数据会发什么;
快速排序和归并排序的原理,以及时间、空间复杂度解释一下,并且让手撕代码;
10亿个数据对象(其中包含属性最早创建时间createTime),求其中最早的十个有什么方法?那自己设计一个数据结构该怎么设计?
手撕 NC50 链表中的节点每k个一组翻转(原题稍有变更);
手撕模拟多线程实现银行转帐(未同步与同步);
你平时是怎么学习新技术的?
你还有什么想问的吗?
总结:三分天注定,七分靠打拼。剩下九十分看面试官心情。
面完10分钟通知一面过了,等待下一面。
作者:ce、欢笙
链接:https://www.nowcoder.com/discuss/685998?source_id=discuss_experience_nctrack&channel=-1
来源:牛客网
牛客网面经10(2年)
阿里开发岗一面面经(社招)
ce、欢笙
编辑于 2021-07-19 10:40:34APP内打开赞 3 | 收藏 79 | 回复5 | 浏览6949阿里开发岗一面面经(社招)APP内打开 3 79 5 分享
最近在考虑跳槽,就斗胆面了些公司。把菜鸡面经分享给大家也算是攒人品了。
阿里
一面
1.synchronized原理,怎么保证可重入性,可见性,抛异常怎么办,和lock锁的区别,2个线程同时访问synchronized的静态方法,2个线程同时访问一个synchronized静态方法和非静态方法,分别怎么进行
2.volatile作用,原理,怎么保证可见性的,内存屏障
3.你了解那些锁,乐观锁和悲观锁,为什么读要加锁,乐观锁为什么适合读场景,写场景不行么,会有什么问题,cas原理
4.什么情况下产生死锁,怎么排查,怎么解决
5.一致性hash原理,解决什么问题,数据倾斜,为什么是2的32次方,20次方可以么
6.redis缓存穿透,布隆过滤器,怎么使用,有什么问题,怎么解决这个问题
7.redis分布式锁,过期时间怎么定的,如果一个业务执行时间比较长,锁过期了怎么办,怎么保证释放锁的一个原子性,你们redis是集群的么,讲讲redlock算法
8.mysql事务,acid,实现原理,脏读,脏写,隔离级别,实现原理,mvcc,幻读,间隙锁原理,什么情况下会使用间隙锁,锁失效怎么办,其他锁了解么,行锁,表锁
9.mysql索引左前缀原理,怎么优化,哪些字段适合建索引,索引有什么优缺点
10.线上遇到过慢查询么,怎么定位,优化的,explain,using filesort表示什么意思,产生原因,怎么解决
11.怎么理解幂等性,有遇到过实际场景么,怎么解决的,为什么用redis,redis过期了或者数据没了怎么办
二面
1.hashmap原理,put和get,为什么是8转红黑树,红黑树节点添加过程,什么时候扩容,为什么是0.75,扩容步骤,为什么分高低位,1.7到1.8有什么优化,hash算法做了哪些优化,头插法有什么问题,为什么线程不安全
2.arraylist原理,为什么数组加transient,add和get时间复杂度,扩容原理,和linkedlist区别,原理,分别在什么场景下使用,为什么
3.了解哪些并发工具类
4.reentrantlock的实现原理,加锁和释放锁的一个过程,aqs,公平和非公平,可重入,可中断怎么实现的
5.concurrenthashmap原理,put,get,size,扩容,怎么保证线程安全的,1.7和1.8的区别,为什么用synchronized,分段锁有什么问题,hash算法做了哪些优化
6.threadlocal用过么,什么场景下使用的,原理,hash冲突怎么办,扩容实现,会有线程安全问题么,内存泄漏产生原因,怎么解决
7.垃圾收集算法,各有什么优缺点,gc roots有哪些,什么情况下会发生full gc
8.了解哪些设计模式,工厂,策略,装饰者,桥接模式讲讲,单例模式会有什么问题
9.对spring aop的理解,解决什么问题,实现原理,jdk动态代理,cglib区别,优缺点,怎么实现方法的调用的
10.mysql中有一个索引(a,b,c),有一条sql,where a = 1 and b > 1 and c =1;可以用到索引么,为什么没用到,B+树的结构,为什么不用红黑树,B树,一千万的数据大概多少次io
11.mysql聚簇索引,覆盖索引,底层结构,主键索引,没有主键怎么办,会自己生成主键为什么还要自定义主键,自动生成的主键有什么问题
12.redis线程模型,单线程有什么优缺点,为什么单线程能保证高性能,什么情况下会出现阻塞,怎么解决
13.kafka是怎么保证高可用性的,讲讲它的设计架构,为什么读写都在主分区,这样有什么优缺点
了解DDD么,不是很了解
你平时是怎么学习的
三面
项目介绍
1.线程有哪些状态,等待状态怎么产生,死锁状态的变化过程,中止状态,interrupt()方法
2.你怎么理解线程安全,哪些场景会产生线程安全问题,有什么解决办法
3.mysql多事务执行会产生哪些问题,怎么解决这些问题
4.分库分表做过么,怎么做到不停机扩容,双写数据丢失怎么办,跨库事务怎么解决
5.你们用的redis集群么,扩容的过程,各个节点间怎么通信的
6.对象一定分配在堆上么,JIT,分层编译,逃逸分析
7.es的写入,查询过程,底层实现,为什么这么设计
8.es集群,脑裂问题,怎么产生的,如何解决
9.while(true)里面一直new thread().start()会有什么问题
10.socket了解么,tcp和udp的实现区别,不了解,用的不多
11.设计一个秒杀系统能承受千万级并发,如果redis也扛不住了怎么办
项目介绍
四面
1.讲讲你最熟悉的技术,jvm,mysql,redis,具体哪方面
2.new Object[100]对象大小,它的一个对象引用大小,对象头结构
3.mysql主从复制,主从延时怎么解决
4.怎么保证redis和mysql的一致性,redis网络原因执行超时了会执行成功么,那不成功怎么保证数据一致性
5.redis持久化过程,aof持久化会出现阻塞么,一般什么情况下使用rdb,aof
6.线上有遇到大流量的情况么,产生了什么问题,为什么数据库2000qps就撑不住了,有想过原因么,你们当时怎么处理的
7.限流怎么做,如果让你设计一个限流系统,怎么实现
8.dubbo和spring cloud区别,具体区别,分别什么场景使用
9.给了几个场景解决分布式事务问题
项目介绍
你觉得你们的业务对公司有什么实际价值,体现在哪,有什么数据指标么
五面
hr面完后又来了一面,说是交叉面
1.怎么理解用户态,内核态,为什么要分级别,有几种转换的方式,怎么转换的,转换失败怎么办
2.怎么理解异常,它的作用是什么,你们工作中是怎么使用的
3.你们用redis么,用来做什么,什么场景使用的,遇到过什么问题,怎么解决的
4.jvm元空间内存结构,永久代有什么问题
5.你平时开发中怎么解决问题,假如现在线上有一个告警,你的解决思路,过程
6.你们为什么要用mq,遇到过什么问题么,怎么就解决的
你觉得和友商相比,你们的优势在哪
聊天:炒股么,为什么买B站,天天用,看好他
转载请注明来源
